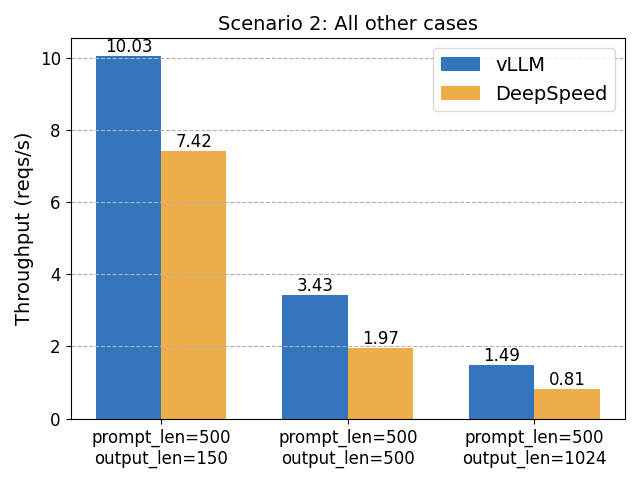
- vLLM matches DeepSpeed-FastGen’s speed in common scenarios and surpasses it when handling longer outputs.
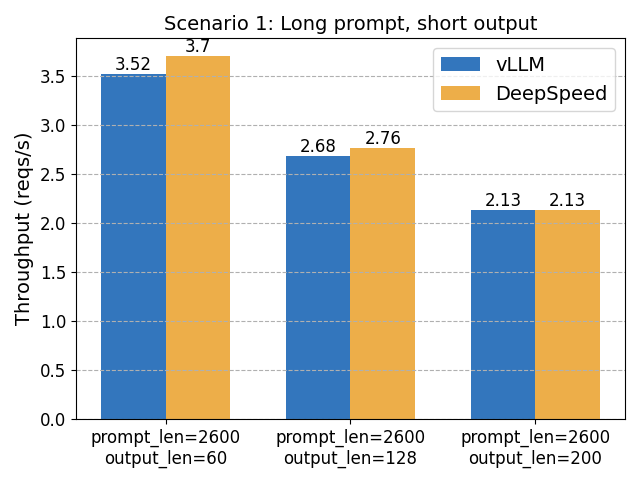
- DeepSpeed-FastGen only outperforms vLLM in scenarios with long prompts and short outputs, due to its Dynamic SplitFuse optimization. This optimization is on vLLM’s roadmap.
- vLLM’s mission is to build the fastest and easiest-to-use open-source LLM inference and serving engine. It is Apache 2.0 and community-owned, offering extensive model and optimization support.
The DeepSpeed team recently published a blog post claiming 2x throughput improvement over vLLM, achieved by leveraging the Dynamic SplitFuse technique. We are happy to see the technology advancements from the open-source community. In this blog, we show the specific scenarios where the Dynamic SplitFuse technique is advantageous, noting that these cases are relatively limited. For the majority of workloads, vLLM is faster than (or performs comparably to) DeepSpeed-FastGen.
Performance Benchmark
We’ve identified two key differences between vLLM and DeepSpeed-FastGen in terms of performance optimization:
- DeepSpeed-FastGen adopts a conservative/suboptimal memory allocation scheme, which wastes memory when output lengths are large.
- DeepSpeed-FastGen’s Dynamic SplitFuse scheduling gives speedup only when prompt lengths are much greater than output lengths.
As a result, DeepSpeed-FastGen outperforms when the workload is consistently long prompt and short output. In other scenarios, vLLM shows superior performance.
We benchmarked the two systems on an NVIDIA A100-80GB GPU with the LLaMA-7B model in the following scenarios:
Scenario 1: Long Prompt Length, Short Output
Here, DeepSpeed-FastGen’s Dynamic SplitFuse scheduling is expected to shine. However, the performance gain we observe isn’t as significant as 2x.
Scenario 2: Other cases
In these cases, vLLM is up to 1.8x faster than DeepSpeed-FastGen.
vLLM’s Future: A True Community Project
We are committed to making vLLM the best open-source project incorporating the community’s best models, optimizations, and hardware. Coming out of UC Berkeley Sky Computing Lab, we are building vLLM truly in open source with the Apache 2.0 license.
The vLLM team prioritizes collaborations and we strive to keep the codebase with high quality code and easy to contribute. We are actively working on system performance; as well as new features like LoRA, Speculative Decoding, and better Quantization Support. Additionally, we are collaborating with hardware vendors like AMD, AWS Inferenetia, and Intel Habana to bring LLM to the broadest community.
Specifically for the Dynamic SplitFuse optimization, we are actively investigating the proper integration. If you have any questions and suggestions, please feel free to contact us on GitHub. We also published the benchmark code here.
Appendix: Feature Comparison
DeepSpeed-FastGen currently offers basic functionalities, supporting only three model types and lacking popular features like stop strings and parallel sampling (e.g., beam search). We do expect the DeepSpeed-FastGen is eager to catch up and we welcome the creative innovation in the market!
| vLLM | DeepSpeed-FastGen | |
|---|---|---|
| Runtime | Python/PyTorch | Python/PyTorch |
| Model implementation | HuggingFace Transformers | Custom implementation + converter for HF models |
| Server frontend | Simple FastAPI server for demo purposes | Custom gRPC-based server |
| Scheduling | Continuous batching | Dynamic SplitFuse |
| Attention kernel | PagedAttention & FlashAttention | PagedAttention & FlashAttention |
| Custom kernels (for LLaMA) | Attention, RoPE, RMS, SILU | Attention, RoPE, RMS, SILU, Embedding |
| KV Cache allocation | Near-optimal | Suboptimal/conservative |
| Supported models | 16 different architectures | LLaMA, Mistral, OPT |
| Sampling methods | Random, parallel, beam search | Random |
| Stop criterion | Stop strings, stop tokens, EOS | EOS |