We are launching GLM-5, targeting complex systems engineering and long-horizon agentic tasks. Scaling is still one of the most important ways to improve the intelligence efficiency of Artificial General Intelligence (AGI). Compared to GLM-4.5, GLM-5 scales from 355B parameters (32B active) to 744B parameters (40B active), and increases pre-training data from 23T to 28.5T tokens. GLM-5 also integrates DeepSeek Sparse Attention (DSA), largely reducing deployment cost while preserving long-context capacity.
Reinforcement learning aims to bridge the gap between competence and excellence in pre-trained models. However, deploying it at scale for LLMs is a challenge due to the RL training inefficiency. To this end, we developed slime, a novel asynchronous RL infrastructure that substantially improves training throughput and efficiency, enabling more fine-grained post-training iterations. With advances in both pre-training and post-training, GLM-5 delivers significant improvement compared to GLM-4.7 across a wide range of academic benchmarks and achieves best-in-class performance among all open-source models in the world on reasoning, coding, and agentic tasks, closing the gap with frontier models.
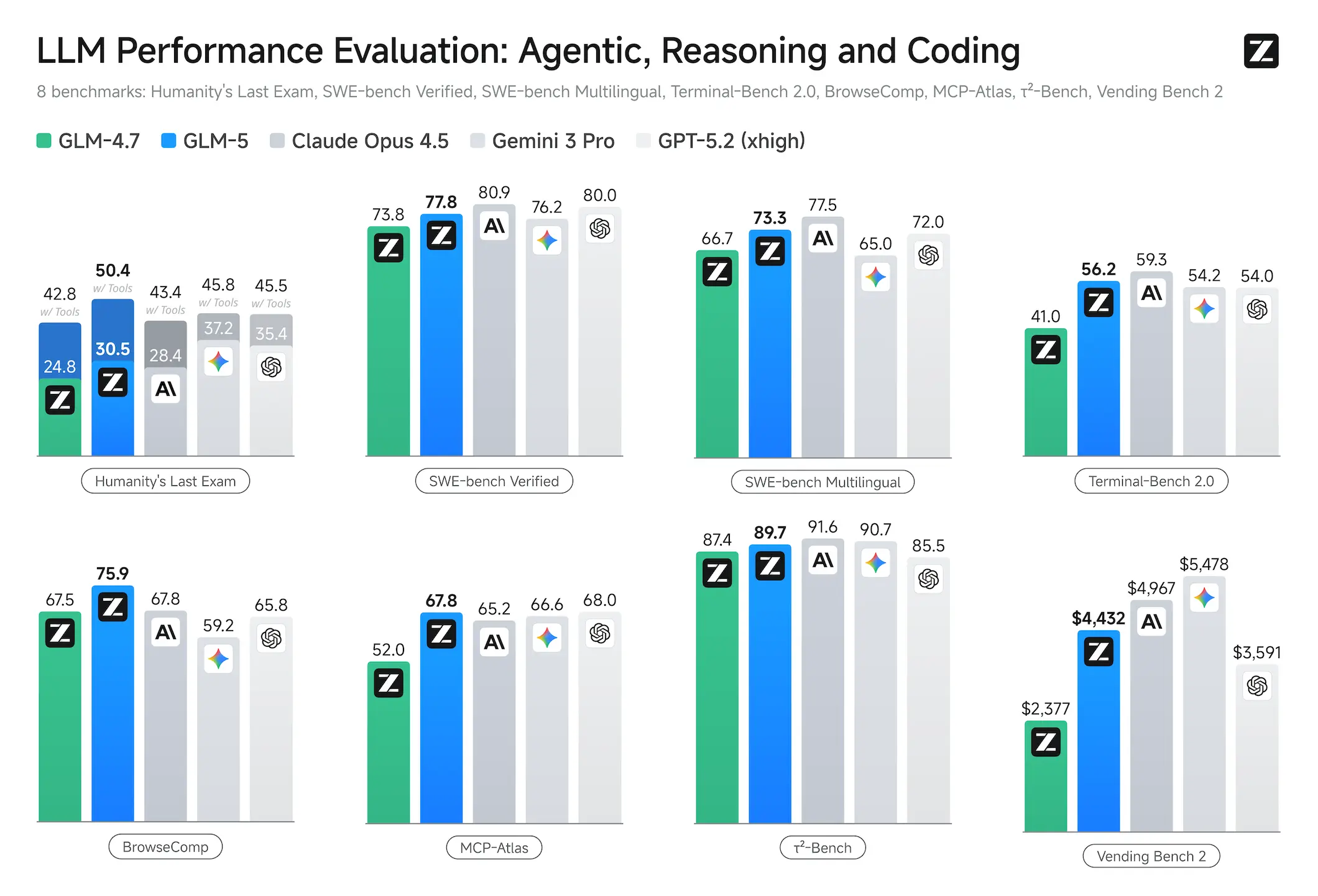
GLM-5 is purpose-built for complex systems engineering and long-horizon agentic tasks. On our internal evaluation suite CC-Bench-V2, GLM-5 significantly outperforms GLM-4.7 across frontend, backend, and long-horizon tasks, narrowing the gap to Claude Opus 4.5.

Model Downloads
| Model | Download Links | Model Size | Precision |
|---|---|---|---|
| GLM-5 | 🤗 Hugging Face 🤖 ModelScope | 744B-A40B | BF16 |
| GLM-5-FP8 | 🤗 Hugging Face 🤖 ModelScope | 744B-A40B | FP8 |
Serve GLM-5 Locally
Prepare environment
vLLM, SGLang, and xLLM all support local deployment of GLM-5. A simple deployment guide is provided here.
vLLM
Using Docker (version 0.18.0 or higher):
docker pull vllm/vllm-openai:v0.18.0then upgrade transformers (version 5.3.0 or higher):
pip install -U transformersSGLang
Using Docker as:
docker pull lmsysorg/sglang:glm5-hopper # For Hopper GPU docker pull lmsysorg/sglang:glm5-blackwell # For Blackwell GPU
Deploy
vLLM
vllm serve zai-org/GLM-5-FP8 \ --tensor-parallel-size 8 \ --gpu-memory-utilization 0.85 \ --speculative-config.method mtp \ --speculative-config.num_speculative_tokens 1 \ --tool-call-parser glm47 \ --reasoning-parser glm45 \ --enable-auto-tool-choice \ --served-model-name glm-5-fp8Check the recipes for more details.
SGLang
sglang serve \ --model-path zai-org/GLM-5-FP8 \ --tp-size 8 \ --tool-call-parser glm47 \ --reasoning-parser glm45 \ --speculative-algorithm EAGLE \ --speculative-num-steps 3 \ --speculative-eagle-topk 1 \ --speculative-num-draft-tokens 4 \ --mem-fraction-static 0.85 \ --served-model-name glm-5-fp8Check the sglang cookbook for more details.
Citation
If you find GLM-5 useful in your research, please cite our technical report:
@misc{glm5team2026glm5vibecodingagentic,
title={GLM-5: from Vibe Coding to Agentic Engineering},
author={GLM-5-Team and : and Aohan Zeng and Xin Lv and Zhenyu Hou and Zhengxiao Du and Qinkai Zheng and Bin Chen and Da Yin and Chendi Ge and Chenghua Huang and Chengxing Xie and Chenzheng Zhu and Congfeng Yin and Cunxiang Wang and Gengzheng Pan and Hao Zeng and Haoke Zhang and Haoran Wang and Huilong Chen and Jiajie Zhang and Jian Jiao and Jiaqi Guo and Jingsen Wang and Jingzhao Du and Jinzhu Wu and Kedong Wang and Lei Li and Lin Fan and Lucen Zhong and Mingdao Liu and Mingming Zhao and Pengfan Du and Qian Dong and Rui Lu and Shuang-Li and Shulin Cao and Song Liu and Ting Jiang and Xiaodong Chen and Xiaohan Zhang and Xuancheng Huang and Xuezhen Dong and Yabo Xu and Yao Wei and Yifan An and Yilin Niu and Yitong Zhu and Yuanhao Wen and Yukuo Cen and Yushi Bai and Zhongpei Qiao and Zihan Wang and Zikang Wang and Zilin Zhu and Ziqiang Liu and Zixuan Li and Bojie Wang and Bosi Wen and Can Huang and Changpeng Cai and Chao Yu and Chen Li and Chengwei Hu and Chenhui Zhang and Dan Zhang and Daoyan Lin and Dayong Yang and Di Wang and Ding Ai and Erle Zhu and Fangzhou Yi and Feiyu Chen and Guohong Wen and Hailong Sun and Haisha Zhao and Haiyi Hu and Hanchen Zhang and Hanrui Liu and Hanyu Zhang and Hao Peng and Hao Tai and Haobo Zhang and He Liu and Hongwei Wang and Hongxi Yan and Hongyu Ge and Huan Liu and Huanpeng Chu and Jia'ni Zhao and Jiachen Wang and Jiajing Zhao and Jiamin Ren and Jiapeng Wang and Jiaxin Zhang and Jiayi Gui and Jiayue Zhao and Jijie Li and Jing An and Jing Li and Jingwei Yuan and Jinhua Du and Jinxin Liu and Junkai Zhi and Junwen Duan and Kaiyue Zhou and Kangjian Wei and Ke Wang and Keyun Luo and Laiqiang Zhang and Leigang Sha and Liang Xu and Lindong Wu and Lintao Ding and Lu Chen and Minghao Li and Nianyi Lin and Pan Ta and Qiang Zou and Rongjun Song and Ruiqi Yang and Shangqing Tu and Shangtong Yang and Shaoxiang Wu and Shengyan Zhang and Shijie Li and Shuang Li and Shuyi Fan and Wei Qin and Wei Tian and Weining Zhang and Wenbo Yu and Wenjie Liang and Xiang Kuang and Xiangmeng Cheng and Xiangyang Li and Xiaoquan Yan and Xiaowei Hu and Xiaoying Ling and Xing Fan and Xingye Xia and Xinyuan Zhang and Xinze Zhang and Xirui Pan and Xu Zou and Xunkai Zhang and Yadi Liu and Yandong Wu and Yanfu Li and Yidong Wang and Yifan Zhu and Yijun Tan and Yilin Zhou and Yiming Pan and Ying Zhang and Yinpei Su and Yipeng Geng and Yong Yan and Yonglin Tan and Yuean Bi and Yuhan Shen and Yuhao Yang and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yurong Wu and Yutao Zhang and Yuxi Duan and Yuxuan Zhang and Zezhen Liu and Zhengtao Jiang and Zhenhe Yan and Zheyu Zhang and Zhixiang Wei and Zhuo Chen and Zhuoer Feng and Zijun Yao and Ziwei Chai and Ziyuan Wang and Zuzhou Zhang and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
year={2026},
eprint={2602.15763},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2602.15763},
}