The GLM-4.x series models are foundation models designed for intelligent agents. GLM-4.7 has 355 billion total parameters with 32 billion active parameters, while GLM-4.5-Air adopts a more compact design with 106 billion total parameters and 12 billion active parameters. GLM-4.x models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Model Introduction
GLM-4.7
GLM-4.7, your new coding partner, is coming with the following features:
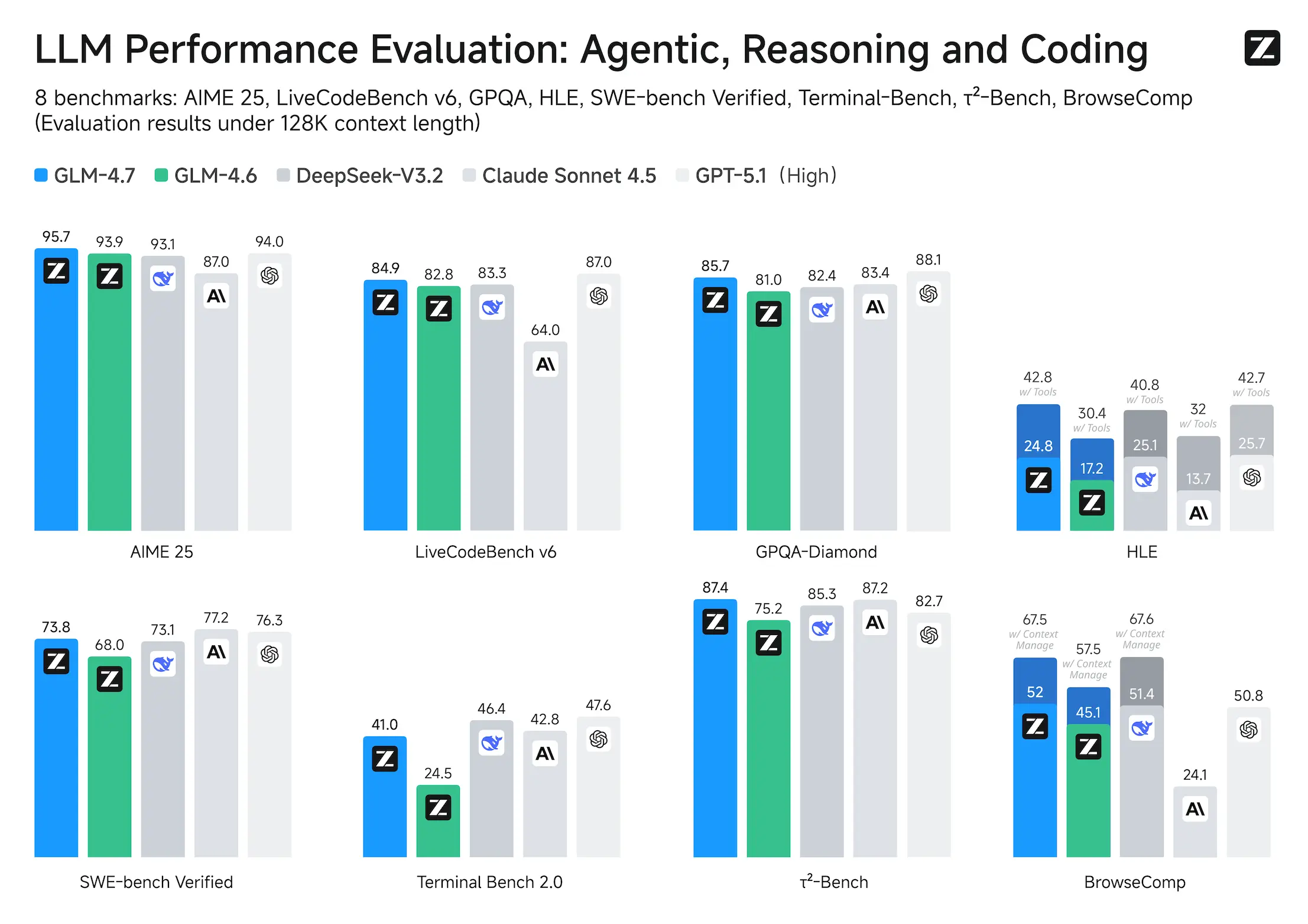
- Core Coding: GLM-4.7 brings clear gains, compared to its predecessor GLM-4.6, in multilingual agentic coding and terminal-based tasks, including (73.8%, +5.8%) on SWE-bench, (66.7%, +12.9%) on SWE-bench Multilingual, and (41%, +16.5%) on Terminal Bench 2.0. GLM-4.7 also supports thinking before acting, with significant improvements on complex tasks in mainstream agent frameworks such as Claude Code, Kilo Code, Cline, and Roo Code.
- Vibe Coding: GLM-4.7 takes a big step forward in improving UI quality. It produces cleaner, more modern webpages and generates better-looking slides with more accurate layout and sizing.
- Tool Using: GLM-4.7 achieves significantly improvements in Tool using. Significant better performances can be seen on benchmarks such as τ^2-Bench and on web browsing via BrowseComp.
- Complex Reasoning: GLM-4.7 delivers a substantial boost in mathematical and reasoning capabilities, achieving (42.8%, +12.4%) on the HLE (Humanity’s Last Exam) benchmark compared to GLM-4.6.
More general, one would also witness significant improvements in many other scenarios such as chat, creative writing, and role-play scenario.
Interleaved Thinking & Preserved Thinking
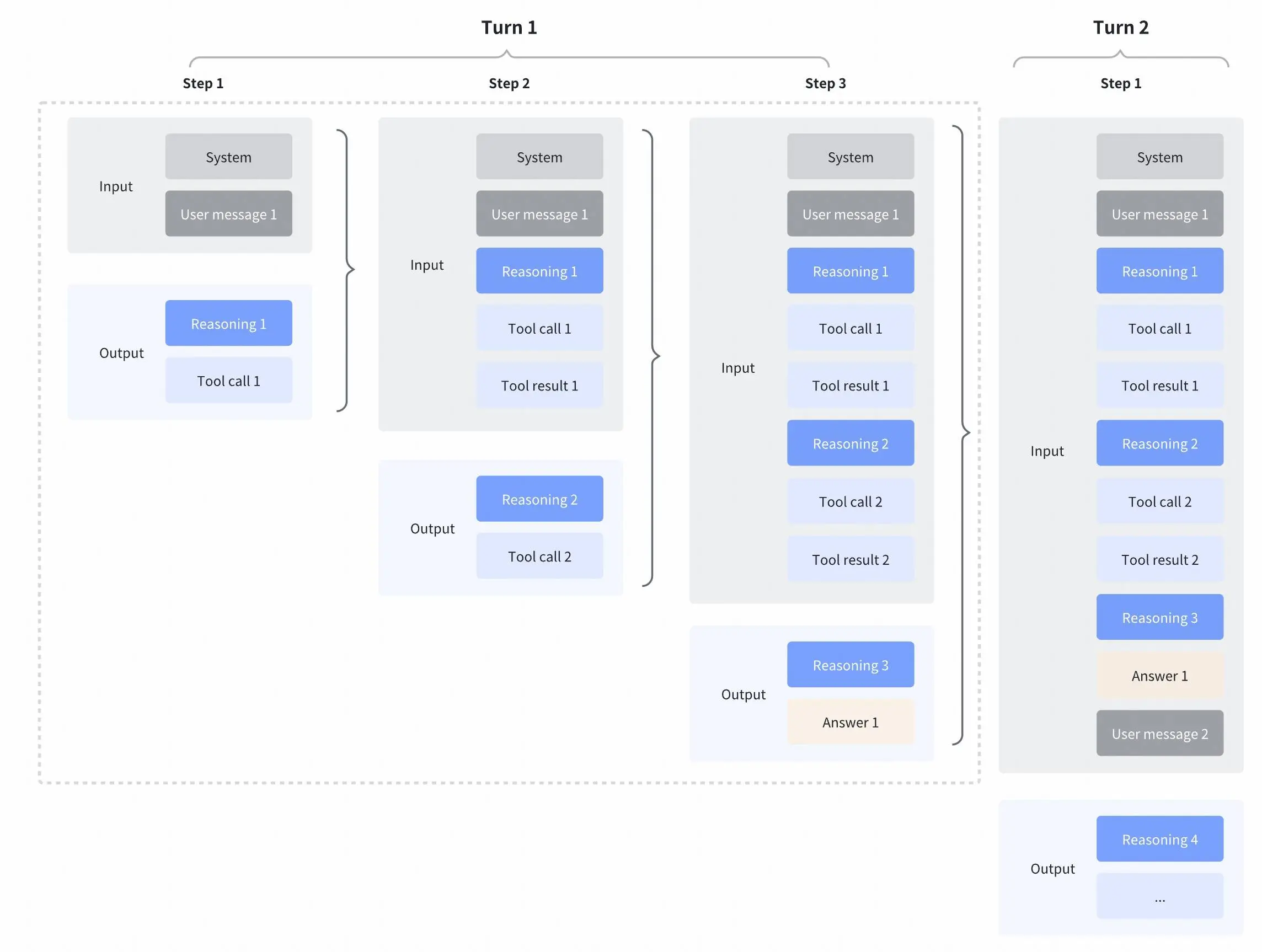
GLM-4.7 further enhances Interleaved Thinking (a feature introduced since GLM-4.5) and introduces Preserved Thinking and Turn-level Thinking. By thinking between actions and staying consistent across turns, it makes complex tasks more stable and more controllable:
- Interleaved Thinking: The model thinks before every response and tool calling, improving instruction following and the quality of generation.
- Preserved Thinking: In coding agent scenarios, the model automatically retains all thinking blocks across multi-turn conversations, reusing the existing reasoning instead of re-deriving from scratch. This reduces information loss and inconsistencies, and is well-suited for long-horizon, complex tasks.
- Turn-level Thinking: The model supports per-turn control over reasoning within a session—disable thinking for lightweight requests to reduce latency/cost, enable it for complex tasks to improve accuracy and stability.
More details: https://docs.z.ai/guides/capabilities/thinking-mode
GLM-4.6
Compared with GLM-4.5, GLM-4.6 brings several key improvements:
- Longer context window: The context window has been expanded from 128K to 200K tokens, enabling the model to handle more complex agentic tasks.
- Superior coding performance: The model achieves higher scores on code benchmarks and demonstrates better real-world performance in applications such as Claude Code、Cline、Roo Code and Kilo Code, including improvements in generating visually polished front-end pages.
- Advanced reasoning: GLM-4.6 shows a clear improvement in reasoning performance and supports tool use during inference, leading to stronger overall capability.
- More capable agents: GLM-4.6 exhibits stronger performance in tool using and search-based agents, and integrates more effectively within agent frameworks.
- Refined writing: Better aligns with human preferences in style and readability, and performs more naturally in role-playing scenarios.
We evaluated GLM-4.6 across eight public benchmarks covering agents, reasoning, and coding. Results show clear gains over GLM-4.5, with GLM-4.6 also holding competitive advantages over leading domestic and international models such as DeepSeek-V3.1-Terminus and Claude Sonnet 4.
GLM-4.5
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of 63.2, in the 3rd place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at 59.8 while maintaining superior efficiency.
For more eval results, show cases, and technical details, please visit our technical report.
The model code, tool parser and reasoning parser can be found in the implementation of transformers, vLLM and SGLang.
Model Architecture and Highlights
GLM-4.x adopts a MoE architecture with loss-free balance routing and sigmoid gates, enhancing compute efficiency. Compared to models like DeepSeek-V3 and Kimi K2, we prioritize depth over width—fewer experts and smaller hidden dimensions, but more layers—resulting in better reasoning performance.
Key architectural designs and highlights:
- Grouped-Query Attention with partial RoPE
- 96 attention heads for 5120 hidden size (2.5× more than typical), improving reasoning on MMLU/BBH despite similar training loss
- QK-Norm for stabilized attention logits
- Muon optimizer, enabling faster convergence and larger batch sizes
- MTP (Multi-Token Prediction) head for speculative decoding
- RL training is powered by the open-source framework slime, which was earlier open-sourced by THUDM.
Performance
We compare GLM-4.5 with various models from OpenAI, Anthropic, Google DeepMind, xAI, Alibaba, Moonshot, and DeepSeek on 12 benchmarks covering agentic (3), reasoning (7), and Coding (2). Overall, GLM-4.5 is ranked at the 3rd place and GLM-4.5 Air is ranked at the 6th.
Agentic Abilities
GLM-4.5 supports 128k context and native function calling. On both $\tau$-bench and BFCL-v3, it matches Claude 4 Sonnet, and on the BrowseComp web browsing benchmark, it surpasses Claude 4 Opus (26.4% vs. 18.8%) and approaches GPT o4-mini-high (28.3%). Its high tool-calling success rate (90.6%) highlights its reliability in agent-based workflows.
Reasoning
GLM-4.5 excels in mathematical and logical reasoning. It scores competitively on MMLU Pro (84.6), AIME-24 (91.0), and MATH500 (98.2), and demonstrates strong generalization across benchmarks like GPQA, LCB, and AA-Index.
Coding
GLM-4.5 shows comprehensive full-stack development ability and ranks among the top models on SWE-bench Verified (64.2) and Terminal-Bench (37.5). In head-to-head evaluations, it achieves a 53.9% win rate over Kimi K2 and 80.8% over Qwen3-Coder. Its high agentic reliability, multi-round coding task performance, and visual interface quality demonstrate its strength as an autonomous coding assistant.
Conclusion
The GLM-4.5 series represents a new wave of large language models, excelling in long-context reasoning, agentic workflows, and coding tasks. Its hybrid MoE architecture—enhanced by techniques like grouped-query attention, MTP, and RL training—offers both efficiency and strong capability.
SGLang provides a production-ready, high-performance inference stack, enabling seamless deployment through advanced memory management and request batching.
Together, GLM-4.5 and SGLang form a robust foundation for next-generation AI—powering intelligent, scalable solutions across code, documents, and agents.
Model Downloads
You can directly experience the model on Hugging Face or ModelScope or download the model by following the links below.
| Model | Download Links | Model Size | Precision |
|---|---|---|---|
| GLM-4.7 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.7-FP8 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | FP8 |
| GLM-4.6 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.6-FP8 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | FP8 |
| GLM-4.5 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.5-Air | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | BF16 |
| GLM-4.5-FP8 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | FP8 |
| GLM-4.5-Air-FP8 | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | FP8 |
| GLM-4.5-Base | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.5-Air-Base | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | BF16 |
The model code, tool parser and reasoning parser can be found in the implementation of transformers, vLLM and SGLang.
System Requirements
Inference
We provide minimum and recommended configurations for “full-featured” model inference. The data in the table below is based on the following conditions:
- All models use MTP layers and specify
--speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4to ensure competitive inference speed. - The
cpu-offloadparameter is not used. - Inference batch size does not exceed
8. - All are executed on devices that natively support FP8 inference, ensuring both weights and cache are in FP8 format.
- Server memory must exceed
1Tto ensure normal model loading and operation.
The models can run under the configurations in the table below:
| Model | Precision | GPU Type and Count | Test Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Under the configurations in the table below, the models can utilize their full 128K context length:
| Model | Precision | GPU Type and Count | Test Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
Fine-tuning
The code can run under the configurations in the table below using Llama Factory:
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
The code can run under the configurations in the table below using Swift:
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
Quick Start
vLLM and SGLang only support GLM-4.7 on their main branches. you can use their official docker images for inference.
vLLM
Using Docker as:
docker pull vllm/vllm-openai:nightly
or using pip (must use pypi.org as the index url):
pip install -U vllm --pre --index-url https://pypi.org/simple --extra-index-url https://wheels.vllm.ai/nightly
SGLang
Using Docker as:
docker pull lmsysorg/sglang:dev
or using pip install sglang from source.
For GLM-4.6 and GLM-4.5, you can follow the configuration in requirements.txt.
transformers
Please refer to the trans_infer_cli.py code in the inference folder.
vLLM
vllm serve zai-org/GLM-4.7-FP8 \
--tensor-parallel-size 4 \
--speculative-config.method mtp \
--speculative-config.num_speculative_tokens 1 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.7-fp8
SGLang
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.7-FP8 \
--tp-size 8 \
--tool-call-parser glm47 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.8 \
--served-model-name glm-4.7-fp8 \
--host 0.0.0.0 \
--port 8000
- PD-Disaggregation
The following is a simple method to implement PD-Disaggregation using a single machine with multiple GPUs, P and D each use 4 GPUs for GLM-4.5
python -m sglang.launch_server --model-path zai-org/GLM-4.5-Air --disaggregation-mode prefill --disaggregation-ib-device mlx5_0 --tp-size 4
python -m sglang.launch_server --model-path zai-org/GLM-4.5-Air --disaggregation-mode decode --port 30001 --disaggregation-ib-device mlx5_0 --tp-size 4 --base-gpu-id 4
python -m sglang_router.launch_router --pd-disaggregation --prefill http://127.0.0.1:30000 --decode http://127.0.0.1:30001 --host 0.0.0.0 --port 8000
Parameter Instructions
For GLM-4.7,
--tool-call-parsershould be set toglm47in bothvLLMandSGLangmethod.For agentic tasks of GLM-4.7, please turn on Preserved Thinking mode by adding the following config (only sglang support):
"chat_template_kwargs": { "enable_thinking": true, "clear_thinking": false }When using
vLLMandSGLang, thinking mode is enabled by default when sending requests. If you want to disable the thinking switch, you need to add theextra_body={"chat_template_kwargs": {"enable_thinking": False}}parameter.Both support tool calling. Please use OpenAI-style tool description format for calls.
For specific code, please refer to
api_request.pyin theinferencefolder.
Evaluation
- For tool-integrated reasoning, please refer to this doc.
- For search benchmark, we design a specific format for searching toolcall in thinking mode to support search agent, please refer to this. for the detailed template.
Citation
If you find our work useful in your research, please consider citing the following paper:
@misc{5team2025glm45agenticreasoningcoding,
title={GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models},
author={GLM Team and Aohan Zeng and Xin Lv and Qinkai Zheng and Zhenyu Hou and Bin Chen and Chengxing Xie and Cunxiang Wang and Da Yin and Hao Zeng and Jiajie Zhang and Kedong Wang and Lucen Zhong and Mingdao Liu and Rui Lu and Shulin Cao and Xiaohan Zhang and Xuancheng Huang and Yao Wei and Yean Cheng and Yifan An and Yilin Niu and Yuanhao Wen and Yushi Bai and Zhengxiao Du and Zihan Wang and Zilin Zhu and Bohan Zhang and Bosi Wen and Bowen Wu and Bowen Xu and Can Huang and Casey Zhao and Changpeng Cai and Chao Yu and Chen Li and Chendi Ge and Chenghua Huang and Chenhui Zhang and Chenxi Xu and Chenzheng Zhu and Chuang Li and Congfeng Yin and Daoyan Lin and Dayong Yang and Dazhi Jiang and Ding Ai and Erle Zhu and Fei Wang and Gengzheng Pan and Guo Wang and Hailong Sun and Haitao Li and Haiyang Li and Haiyi Hu and Hanyu Zhang and Hao Peng and Hao Tai and Haoke Zhang and Haoran Wang and Haoyu Yang and He Liu and He Zhao and Hongwei Liu and Hongxi Yan and Huan Liu and Huilong Chen and Ji Li and Jiajing Zhao and Jiamin Ren and Jian Jiao and Jiani Zhao and Jianyang Yan and Jiaqi Wang and Jiayi Gui and Jiayue Zhao and Jie Liu and Jijie Li and Jing Li and Jing Lu and Jingsen Wang and Jingwei Yuan and Jingxuan Li and Jingzhao Du and Jinhua Du and Jinxin Liu and Junkai Zhi and Junli Gao and Ke Wang and Lekang Yang and Liang Xu and Lin Fan and Lindong Wu and Lintao Ding and Lu Wang and Man Zhang and Minghao Li and Minghuan Xu and Mingming Zhao and Mingshu Zhai and Pengfan Du and Qian Dong and Shangde Lei and Shangqing Tu and Shangtong Yang and Shaoyou Lu and Shijie Li and Shuang Li and Shuang-Li and Shuxun Yang and Sibo Yi and Tianshu Yu and Wei Tian and Weihan Wang and Wenbo Yu and Weng Lam Tam and Wenjie Liang and Wentao Liu and Xiao Wang and Xiaohan Jia and Xiaotao Gu and Xiaoying Ling and Xin Wang and Xing Fan and Xingru Pan and Xinyuan Zhang and Xinze Zhang and Xiuqing Fu and Xunkai Zhang and Yabo Xu and Yandong Wu and Yida Lu and Yidong Wang and Yilin Zhou and Yiming Pan and Ying Zhang and Yingli Wang and Yingru Li and Yinpei Su and Yipeng Geng and Yitong Zhu and Yongkun Yang and Yuhang Li and Yuhao Wu and Yujiang Li and Yunan Liu and Yunqing Wang and Yuntao Li and Yuxuan Zhang and Zezhen Liu and Zhen Yang and Zhengda Zhou and Zhongpei Qiao and Zhuoer Feng and Zhuorui Liu and Zichen Zhang and Zihan Wang and Zijun Yao and Zikang Wang and Ziqiang Liu and Ziwei Chai and Zixuan Li and Zuodong Zhao and Wenguang Chen and Jidong Zhai and Bin Xu and Minlie Huang and Hongning Wang and Juanzi Li and Yuxiao Dong and Jie Tang},
year={2025},
eprint={2508.06471},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2508.06471},
}