The GLM-4.5 series models are foundation models designed for intelligent agents. GLM-4.5 has 355 billion total parameters with 32 billion active parameters, while GLM-4.5-Air adopts a more compact design with 106 billion total parameters and 12 billion active parameters. GLM-4.5 models unify reasoning, coding, and intelligent agent capabilities to meet the complex demands of intelligent agent applications.
Both GLM-4.5 and GLM-4.5-Air are hybrid reasoning models that provide two modes: thinking mode for complex reasoning and tool usage, and non-thinking mode for immediate responses.
We have open-sourced the base models, hybrid reasoning models, and FP8 versions of the hybrid reasoning models for both GLM-4.5 and GLM-4.5-Air. They are released under the MIT open-source license and can be used commercially and for secondary development.
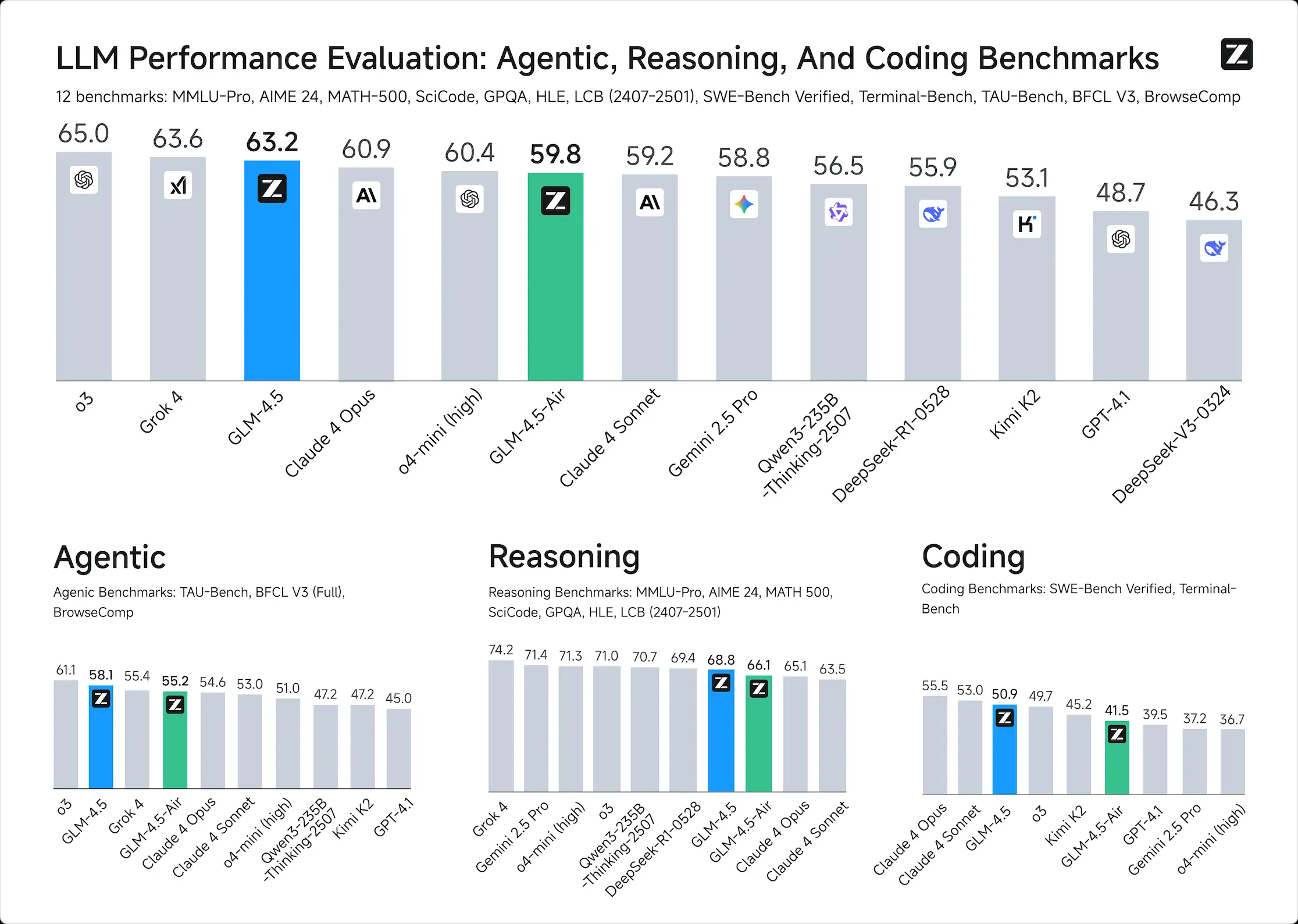
As demonstrated in our comprehensive evaluation across 12 industry-standard benchmarks, GLM-4.5 achieves exceptional performance with a score of 63.2, in the 3rd place among all the proprietary and open-source models. Notably, GLM-4.5-Air delivers competitive results at 59.8 while maintaining superior efficiency.
For more eval results, show cases, and technical details, please visit our technical blog. The technical report will be released soon.
The model code, tool parser and reasoning parser can be found in the implementation of transformers, vLLM and SGLang.
Model Architecture and Highlights
GLM-4.5 adopts a MoE architecture with loss-free balance routing and sigmoid gates, enhancing compute efficiency. Compared to models like DeepSeek-V3 and Kimi K2, we prioritize depth over width—fewer experts and smaller hidden dimensions, but more layers—resulting in better reasoning performance.
Key architectural designs and highlights:
- Grouped-Query Attention with partial RoPE
- 96 attention heads for 5120 hidden size (2.5× more than typical), improving reasoning on MMLU/BBH despite similar training loss
- QK-Norm for stabilized attention logits
- Muon optimizer, enabling faster convergence and larger batch sizes
- MTP (Multi-Token Prediction) head for speculative decoding
- RL training is powered by the open-source framework slime, which was earlier open-sourced by THUDM.
Performance
We compare GLM-4.5 with various models from OpenAI, Anthropic, Google DeepMind, xAI, Alibaba, Moonshot, and DeepSeek on 12 benchmarks covering agentic (3), reasoning (7), and Coding (2). Overall, GLM-4.5 is ranked at the 3rd place and GLM-4.5 Air is ranked at the 6th.
Agentic Abilities
GLM-4.5 supports 128k context and native function calling. On both $\tau$-bench and BFCL-v3, it matches Claude 4 Sonnet, and on the BrowseComp web browsing benchmark, it surpasses Claude 4 Opus (26.4% vs. 18.8%) and approaches GPT o4-mini-high (28.3%). Its high tool-calling success rate (90.6%) highlights its reliability in agent-based workflows.
Reasoning
GLM-4.5 excels in mathematical and logical reasoning. It scores competitively on MMLU Pro (84.6), AIME-24 (91.0), and MATH500 (98.2), and demonstrates strong generalization across benchmarks like GPQA, LCB, and AA-Index.
Coding
GLM-4.5 shows comprehensive full-stack development ability and ranks among the top models on SWE-bench Verified (64.2) and Terminal-Bench (37.5). In head-to-head evaluations, it achieves a 53.9% win rate over Kimi K2 and 80.8% over Qwen3-Coder. Its high agentic reliability, multi-round coding task performance, and visual interface quality demonstrate its strength as an autonomous coding assistant.
Conclusion
The GLM-4.5 series represents a new wave of large language models, excelling in long-context reasoning, agentic workflows, and coding tasks. Its hybrid MoE architecture—enhanced by techniques like grouped-query attention, MTP, and RL training—offers both efficiency and strong capability.
SGLang provides a production-ready, high-performance inference stack, enabling seamless deployment through advanced memory management and request batching.
Together, GLM-4.5 and SGLang form a robust foundation for next-generation AI—powering intelligent, scalable solutions across code, documents, and agents.
Model Downloads
You can directly experience the model on Hugging Face or ModelScope or download the model by following the links below.
| Model | Download Links | Model Size | Precision |
|---|---|---|---|
| GLM-4.5 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.5-Air | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | BF16 |
| GLM-4.5-FP8 | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | FP8 |
| GLM-4.5-Air-FP8 | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | FP8 |
| GLM-4.5-Base | 🤗 Hugging Face 🤖 ModelScope | 355B-A32B | BF16 |
| GLM-4.5-Air-Base | 🤗 Hugging Face 🤖 ModelScope | 106B-A12B | BF16 |
System Requirements
Inference
We provide minimum and recommended configurations for “full-featured” model inference. The data in the table below is based on the following conditions:
- All models use MTP layers and specify
--speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4to ensure competitive inference speed. - The
cpu-offloadparameter is not used. - Inference batch size does not exceed
8. - All are executed on devices that natively support FP8 inference, ensuring both weights and cache are in FP8 format.
- Server memory must exceed
1Tto ensure normal model loading and operation.
The models can run under the configurations in the table below:
| Model | Precision | GPU Type and Count | Test Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5 | FP8 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | BF16 | H100 x 4 / H200 x 2 | sglang |
| GLM-4.5-Air | FP8 | H100 x 2 / H200 x 1 | sglang |
Under the configurations in the table below, the models can utilize their full 128K context length:
| Model | Precision | GPU Type and Count | Test Framework |
|---|---|---|---|
| GLM-4.5 | BF16 | H100 x 32 / H200 x 16 | sglang |
| GLM-4.5 | FP8 | H100 x 16 / H200 x 8 | sglang |
| GLM-4.5-Air | BF16 | H100 x 8 / H200 x 4 | sglang |
| GLM-4.5-Air | FP8 | H100 x 4 / H200 x 2 | sglang |
Fine-tuning
The code can run under the configurations in the table below using Llama Factory:
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|---|---|---|---|
| GLM-4.5 | H100 x 16 | Lora | 1 |
| GLM-4.5-Air | H100 x 4 | Lora | 1 |
The code can run under the configurations in the table below using Swift:
| Model | GPU Type and Count | Strategy | Batch Size (per GPU) |
|---|---|---|---|
| GLM-4.5 | H20 (96GiB) x 16 | Lora | 1 |
| GLM-4.5-Air | H20 (96GiB) x 4 | Lora | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | SFT | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | SFT | 1 |
| GLM-4.5 | H20 (96GiB) x 128 | RL | 1 |
| GLM-4.5-Air | H20 (96GiB) x 32 | RL | 1 |
Quick Start
Please install the required packages according to requirements.txt.
pip install -r requirements.txt
transformers
Please refer to the trans_infer_cli.py code in the inference folder.
vLLM
- Both BF16 and FP8 can be started with the following code:
vllm serve zai-org/GLM-4.5-Air \
--tensor-parallel-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--enable-auto-tool-choice \
--served-model-name glm-4.5-air
If you’re using 8x H100 GPUs and encounter insufficient memory when running the GLM-4.5 model, you’ll need
--cpu-offload-gb 16 (only applicable to vLLM).
If you encounter flash infer issues, use VLLM_ATTENTION_BACKEND=XFORMERS as a temporary replacement. You can also
specify TORCH_CUDA_ARCH_LIST='9.0+PTX' to use flash infer (different GPUs have different TORCH_CUDA_ARCH_LIST
values, please check accordingly).
SGLang
- BF16
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air \
--tp-size 8 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--served-model-name glm-4.5-air \
--host 0.0.0.0 \
--port 8000
- FP8
python3 -m sglang.launch_server \
--model-path zai-org/GLM-4.5-Air-FP8 \
--tp-size 4 \
--tool-call-parser glm45 \
--reasoning-parser glm45 \
--speculative-algorithm EAGLE \
--speculative-num-steps 3 \
--speculative-eagle-topk 1 \
--speculative-num-draft-tokens 4 \
--mem-fraction-static 0.7 \
--disable-shared-experts-fusion \
--served-model-name glm-4.5-air-fp8 \
--host 0.0.0.0 \
--port 8000
Request Parameter Instructions
- When using
vLLMandSGLang, thinking mode is enabled by default when sending requests. If you want to disable the thinking switch, you need to add theextra_body={"chat_template_kwargs": {"enable_thinking": False}}parameter. - Both support tool calling. Please use OpenAI-style tool description format for calls.
- For specific code, please refer to
api_request.pyin theinferencefolder.