We present a preview version of DeepSeek-V4 series, including two strong Mixture-of-Experts (MoE) language models — DeepSeek-V4-Pro with 1.6T parameters (49B activated) and DeepSeek-V4-Flash with 284B parameters (13B activated) — both supporting a context length of one million tokens.
Introduction
DeepSeek-V4 series incorporate several key upgrades in architecture and optimization:
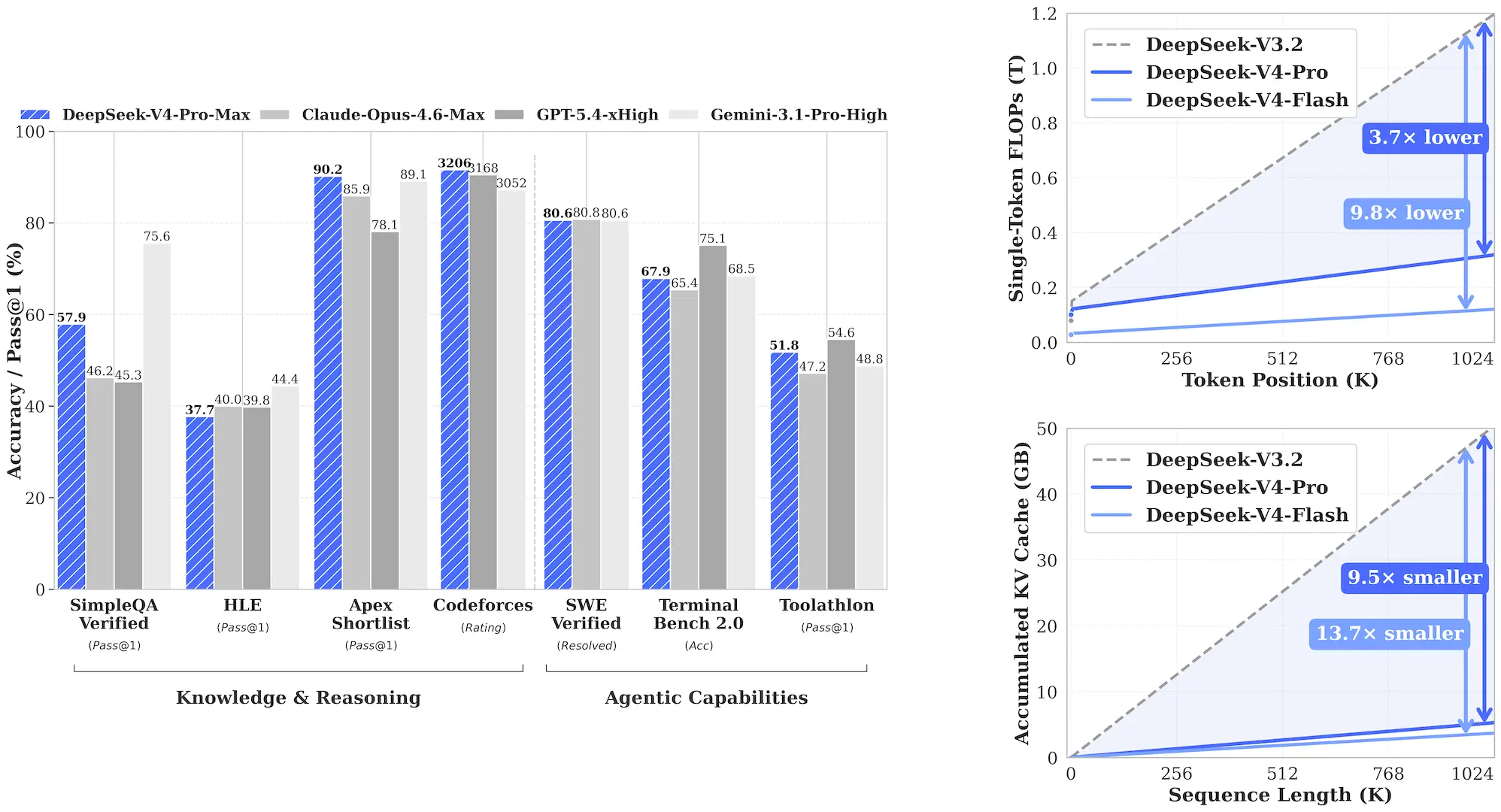
- Hybrid Attention Architecture: We design a hybrid attention mechanism combining Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to dramatically improve long-context efficiency. In the 1M-token context setting, DeepSeek-V4-Pro requires only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2.
- Manifold-Constrained Hyper-Connections (mHC): We incorporate mHC to strengthen conventional residual connections, enhancing stability of signal propagation across layers while preserving model expressivity.
- Muon Optimizer: We employ the Muon optimizer for faster convergence and greater training stability.
We pre-train both models on more than 32T diverse and high-quality tokens, followed by a comprehensive post-training pipeline. The post-training features a two-stage paradigm: independent cultivation of domain-specific experts (through SFT and RL with GRPO), followed by unified model consolidation via on-policy distillation, integrating distinct proficiencies across diverse domains into a single model.
DeepSeek-V4-Pro-Max, the maximum reasoning effort mode of DeepSeek-V4-Pro, significantly advances the knowledge capabilities of open-source models, firmly establishing itself as the best open-source model available today. It achieves top-tier performance in coding benchmarks and significantly bridges the gap with leading closed-source models on reasoning and agentic tasks. Meanwhile, DeepSeek-V4-Flash-Max achieves comparable reasoning performance to the Pro version when given a larger thinking budget, though its smaller parameter scale naturally places it slightly behind on pure knowledge tasks and the most complex agentic workflows.
Model Downloads
| Model | #Total Params | #Activated Params | Context Length | Precision | Download |
|---|---|---|---|---|---|
| DeepSeek-V4-Flash-Base | 284B | 13B | 1M | FP8 Mixed | HuggingFace | ModelScope |
| DeepSeek-V4-Flash | 284B | 13B | 1M | FP4 + FP8 Mixed* | HuggingFace | ModelScope |
| DeepSeek-V4-Pro-Base | 1.6T | 49B | 1M | FP8 Mixed | HuggingFace | ModelScope |
| DeepSeek-V4-Pro | 1.6T | 49B | 1M | FP4 + FP8 Mixed* | HuggingFace | ModelScope |
*FP4 + FP8 Mixed: MoE expert parameters use FP4 precision; most other parameters use FP8.
Evaluation Results
Base Model
| Benchmark (Metric) | # Shots | DeepSeek-V3.2-Base | DeepSeek-V4-Flash-Base | DeepSeek-V4-Pro-Base |
|---|---|---|---|---|
| Architecture | - | MoE | MoE | MoE |
| # Activated Params | - | 37B | 13B | 49B |
| # Total Params | - | 671B | 284B | 1.6T |
| World Knowledge | ||||
| AGIEval (EM) | 0-shot | 80.1 | 82.6 | 83.1 |
| MMLU (EM) | 5-shot | 87.8 | 88.7 | 90.1 |
| MMLU-Redux (EM) | 5-shot | 87.5 | 89.4 | 90.8 |
| MMLU-Pro (EM) | 5-shot | 65.5 | 68.3 | 73.5 |
| MMMLU (EM) | 5-shot | 87.9 | 88.8 | 90.3 |
| C-Eval (EM) | 5-shot | 90.4 | 92.1 | 93.1 |
| CMMLU (EM) | 5-shot | 88.9 | 90.4 | 90.8 |
| MultiLoKo (EM) | 5-shot | 38.7 | 42.2 | 51.1 |
| Simple-QA verified (EM) | 25-shot | 28.3 | 30.1 | 55.2 |
| SuperGPQA (EM) | 5-shot | 45.0 | 46.5 | 53.9 |
| FACTS Parametric (EM) | 25-shot | 27.1 | 33.9 | 62.6 |
| TriviaQA (EM) | 5-shot | 83.3 | 82.8 | 85.6 |
| Language & Reasoning | ||||
| BBH (EM) | 3-shot | 87.6 | 86.9 | 87.5 |
| DROP (F1) | 1-shot | 88.2 | 88.6 | 88.7 |
| HellaSwag (EM) | 0-shot | 86.4 | 85.7 | 88.0 |
| WinoGrande (EM) | 0-shot | 78.9 | 79.5 | 81.5 |
| CLUEWSC (EM) | 5-shot | 83.5 | 82.2 | 85.2 |
| Code & Math | ||||
| BigCodeBench (Pass@1) | 3-shot | 63.9 | 56.8 | 59.2 |
| HumanEval (Pass@1) | 0-shot | 62.8 | 69.5 | 76.8 |
| GSM8K (EM) | 8-shot | 91.1 | 90.8 | 92.6 |
| MATH (EM) | 4-shot | 60.5 | 57.4 | 64.5 |
| MGSM (EM) | 8-shot | 81.3 | 85.7 | 84.4 |
| CMath (EM) | 3-shot | 92.6 | 93.6 | 90.9 |
| Long Context | ||||
| LongBench-V2 (EM) | 1-shot | 40.2 | 44.7 | 51.5 |
Instruct Model
DeepSeek-V4-Pro and DeepSeek-V4-Flash both support three reasoning effort modes:
| Reasoning Mode | Characteristics | Typical Use Cases | Response Format |
|---|---|---|---|
| Non-think | Fast, intuitive responses | Routine daily tasks, low-risk decisions | </think> summary |
| Think High | Conscious logical analysis, slower but more accurate | Complex problem-solving, planning | <think> thinking </think> summary |
| Think Max | Push reasoning to its fullest extent | Exploring the boundary of model reasoning capability | Special system prompt + <think> thinking </think> summary |
DeepSeek-V4-Pro-Max vs Frontier Models
| Benchmark (Metric) | Opus-4.6 Max | GPT-5.4 xHigh | Gemini-3.1-Pro High | K2.6 Thinking | GLM-5.1 Thinking | DS-V4-Pro Max |
|---|---|---|---|---|---|---|
| Knowledge & Reasoning | ||||||
| MMLU-Pro (EM) | 89.1 | 87.5 | 91.0 | 87.1 | 86.0 | 87.5 |
| SimpleQA-Verified (Pass@1) | 46.2 | 45.3 | 75.6 | 36.9 | 38.1 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 76.4 | 76.8 | 85.9 | 75.9 | 75.0 | 84.4 |
| GPQA Diamond (Pass@1) | 91.3 | 93.0 | 94.3 | 90.5 | 86.2 | 90.1 |
| HLE (Pass@1) | 40.0 | 39.8 | 44.4 | 36.4 | 34.7 | 37.7 |
| LiveCodeBench (Pass@1) | 88.8 | - | 91.7 | 89.6 | - | 93.5 |
| Codeforces (Rating) | - | 3168 | 3052 | - | - | 3206 |
| HMMT 2026 Feb (Pass@1) | 96.2 | 97.7 | 94.7 | 92.7 | 89.4 | 95.2 |
| IMOAnswerBench (Pass@1) | 75.3 | 91.4 | 81.0 | 86.0 | 83.8 | 89.8 |
| Apex (Pass@1) | 34.5 | 54.1 | 60.9 | 24.0 | 11.5 | 38.3 |
| Apex Shortlist (Pass@1) | 85.9 | 78.1 | 89.1 | 75.5 | 72.4 | 90.2 |
| Long Context | ||||||
| MRCR 1M (MMR) | 92.9 | - | 76.3 | - | - | 83.5 |
| CorpusQA 1M (ACC) | 71.7 | - | 53.8 | - | - | 62.0 |
| Agentic | ||||||
| Terminal Bench 2.0 (Acc) | 65.4 | 75.1 | 68.5 | 66.7 | 63.5 | 67.9 |
| SWE Verified (Resolved) | 80.8 | - | 80.6 | 80.2 | - | 80.6 |
| SWE Pro (Resolved) | 57.3 | 57.7 | 54.2 | 58.6 | 58.4 | 55.4 |
| SWE Multilingual (Resolved) | 77.5 | - | - | 76.7 | 73.3 | 76.2 |
| BrowseComp (Pass@1) | 83.7 | 82.7 | 85.9 | 83.2 | 79.3 | 83.4 |
| HLE w/ tools (Pass@1) | 53.1 | 52.0 | 51.6 | 54.0 | 50.4 | 48.2 |
| GDPval-AA (Elo) | 1619 | 1674 | 1314 | 1482 | 1535 | 1554 |
| MCPAtlas Public (Pass@1) | 73.8 | 67.2 | 69.2 | 66.6 | 71.8 | 73.6 |
| Toolathlon (Pass@1) | 47.2 | 54.6 | 48.8 | 50.0 | 40.7 | 51.8 |
Comparison across Modes
| Benchmark (Metric) | V4-Flash Non-Think | V4-Flash High | V4-Flash Max | V4-Pro Non-Think | V4-Pro High | V4-Pro Max |
|---|---|---|---|---|---|---|
| Knowledge & Reasoning | ||||||
| MMLU-Pro (EM) | 83.0 | 86.4 | 86.2 | 82.9 | 87.1 | 87.5 |
| SimpleQA-Verified (Pass@1) | 23.1 | 28.9 | 34.1 | 45.0 | 46.2 | 57.9 |
| Chinese-SimpleQA (Pass@1) | 71.5 | 73.2 | 78.9 | 75.8 | 77.7 | 84.4 |
| GPQA Diamond (Pass@1) | 71.2 | 87.4 | 88.1 | 72.9 | 89.1 | 90.1 |
| HLE (Pass@1) | 8.1 | 29.4 | 34.8 | 7.7 | 34.5 | 37.7 |
| LiveCodeBench (Pass@1) | 55.2 | 88.4 | 91.6 | 56.8 | 89.8 | 93.5 |
| Codeforces (Rating) | - | 2816 | 3052 | - | 2919 | 3206 |
| HMMT 2026 Feb (Pass@1) | 40.8 | 91.9 | 94.8 | 31.7 | 94.0 | 95.2 |
| IMOAnswerBench (Pass@1) | 41.9 | 85.1 | 88.4 | 35.3 | 88.0 | 89.8 |
| Apex (Pass@1) | 1.0 | 19.1 | 33.0 | 0.4 | 27.4 | 38.3 |
| Apex Shortlist (Pass@1) | 9.3 | 72.1 | 85.7 | 9.2 | 85.5 | 90.2 |
| Long Context | ||||||
| MRCR 1M (MMR) | 37.5 | 76.9 | 78.7 | 44.7 | 83.3 | 83.5 |
| CorpusQA 1M (ACC) | 15.5 | 59.3 | 60.5 | 35.6 | 56.5 | 62.0 |
| Agentic | ||||||
| Terminal Bench 2.0 (Acc) | 49.1 | 56.6 | 56.9 | 59.1 | 63.3 | 67.9 |
| SWE Verified (Resolved) | 73.7 | 78.6 | 79.0 | 73.6 | 79.4 | 80.6 |
| SWE Pro (Resolved) | 49.1 | 52.3 | 52.6 | 52.1 | 54.4 | 55.4 |
| SWE Multilingual (Resolved) | 69.7 | 70.2 | 73.3 | 69.8 | 74.1 | 76.2 |
| BrowseComp (Pass@1) | - | 53.5 | 73.2 | - | 80.4 | 83.4 |
| HLE w/ tools (Pass@1) | - | 40.3 | 45.1 | - | 44.7 | 48.2 |
| MCPAtlas (Pass@1) | 64.0 | 67.4 | 69.0 | 69.4 | 74.2 | 73.6 |
| GDPval-AA (Elo) | - | - | 1395 | - | - | 1554 |
| Toolathlon (Pass@1) | 40.7 | 43.5 | 47.8 | 46.3 | 49.0 | 51.8 |
Chat Template
This release does not include a Jinja-format chat template. Instead, we provide a dedicated encoding folder with Python scripts and test cases demonstrating how to encode messages in OpenAI-compatible format into input strings for the model, and how to parse the model’s text output.
A brief example:
from encoding_dsv4 import encode_messages, parse_message_from_completion_text
messages = [
{"role": "user", "content": "hello"},
{"role": "assistant", "content": "Hello! I am DeepSeek.", "reasoning_content": "thinking..."},
{"role": "user", "content": "1+1=?"}
]
# messages -> string
prompt = encode_messages(messages, thinking_mode="thinking")
# string -> tokens
import transformers
tokenizer = transformers.AutoTokenizer.from_pretrained("deepseek-ai/DeepSeek-V4-Pro")
tokens = tokenizer.encode(prompt)
How to Run Locally
For local deployment, we recommend setting the sampling parameters to temperature = 1.0, top_p = 1.0. For the Think Max reasoning mode, we recommend setting the context window to at least 384K tokens.
License
This repository and the model weights are licensed under the MIT License.
Citation
@misc{deepseekai2026deepseekv4,
title={DeepSeek-V4: Towards Highly Efficient Million-Token Context Intelligence},
author={DeepSeek-AI},
year={2026},
}
Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.