Introducing DeepSeek LLM, an advanced language model comprising 67 billion parameters. It has been trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese. In order to foster research, we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open source for the research community.
Introduction | Model Download | Quick Start | Evaluation Results | License | Citation
1. Introduction
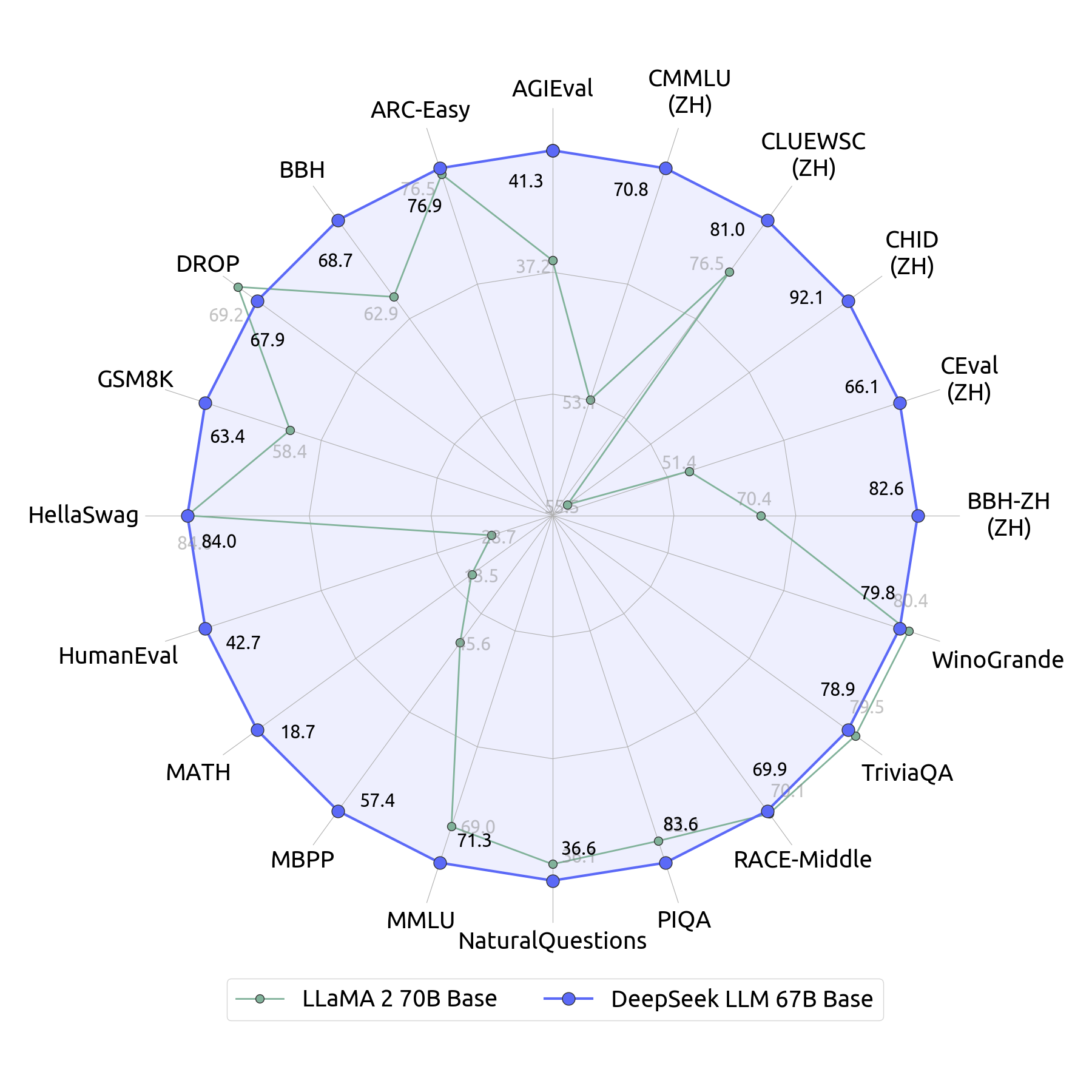
Superior General Capabilities: DeepSeek LLM 67B Base outperforms Llama2 70B Base in areas such as reasoning, coding, math, and Chinese comprehension.
Proficient in Coding and Math: DeepSeek LLM 67B Chat exhibits outstanding performance in coding (HumanEval Pass@1: 73.78) and mathematics (GSM8K 0-shot: 84.1, Math 0-shot: 32.6). It also demonstrates remarkable generalization abilities, as evidenced by its exceptional score of 65 on the Hungarian National High School Exam.
Mastery in Chinese Language: Based on our evaluation, DeepSeek LLM 67B Chat surpasses GPT-3.5 in Chinese.
2. Model Downloads
We release the DeepSeek LLM 7B/67B, including both base and chat models, to the public. To support a broader and more diverse range of research within both academic and commercial communities, we are providing access to the intermediate checkpoints of the base model from its training process. Please note that the use of this model is subject to the terms outlined in License section. Commercial usage is permitted under these terms.
Huggingface
| Model | Sequence Length | Download |
|---|---|---|
| DeepSeek LLM 7B Base | 4096 | 🤗 HuggingFace |
| DeepSeek LLM 7B Chat | 4096 | 🤗 HuggingFace |
| DeepSeek LLM 67B Base | 4096 | 🤗 HuggingFace |
| DeepSeek LLM 67B Chat | 4096 | 🤗 HuggingFace |
Intermediate Checkpoints
We host the intermediate checkpoints of DeepSeek LLM 7B/67B on AWS S3 (Simple Storage Service). These files can be downloaded using the AWS Command Line Interface (CLI).
# using AWS CLI
# DeepSeek-LLM-7B-Base
aws s3 cp s3://deepseek-ai/DeepSeek-LLM/DeepSeek-LLM-7B-Base <local_path> --recursive --request-payer
# DeepSeek-LLM-67B-Base
aws s3 cp s3://deepseek-ai/DeepSeek-LLM/DeepSeek-LLM-67B-Base <local_path> --recursive --request-payer
3. Evaluation Results
Base Model
We evaluate our models and some baseline models on a series of representative benchmarks, both in English and Chinese. In this part, the evaluation results we report are based on the internal, non-open-source hai-llm evaluation framework. Please note that there may be slight discrepancies when using the converted HuggingFace models.
| model | Hella Swag | Trivia QA | MMLU | GSM8K | Human Eval | BBH | CEval | CMMLU | Chinese QA |
|---|---|---|---|---|---|---|---|---|---|
| 0-shot | 5-shot | 5-shot | 8-shot | 0-shot | 3-shot | 5-shot | 5-shot | 5-shot | |
| LLaMA-2 -7B | 75.6 | 63.8 | 45.8 | 15.5 | 14.6 | 38.5 | 33.9 | 32.6 | 21.5 |
| LLaMA-2 -70B | 84.0 | 79.5 | 69.0 | 58.4 | 28.7 | 62.9 | 51.4 | 53.1 | 50.2 |
| DeepSeek LLM 7B Base | 75.4 | 59.7 | 48.2 | 17.4 | 26.2 | 39.5 | 45.0 | 47.2 | 78.0 |
| DeepSeek LLM 67B Base | 84.0 | 78.9 | 71.3 | 63.4 | 42.7 | 68.7 | 66.1 | 70.8 | 87.6 |
Note: ChineseQA is an in-house benchmark, inspired by TriviaQA.
Chat Model
Never Seen Before Exam
To address data contamination and tuning for specific testsets, we have designed fresh problem sets to assess the capabilities of open-source LLM models. The evaluation results indicate that DeepSeek LLM 67B Chat performs exceptionally well on never-before-seen exams.
Hungarian National High-School Exam: In line with Grok-1, we have evaluated the model’s mathematical capabilities using the Hungarian National High School Exam. This exam comprises 33 problems, and the model’s scores are determined through human annotation. We follow the scoring metric in the solution.pdf to evaluate all models.
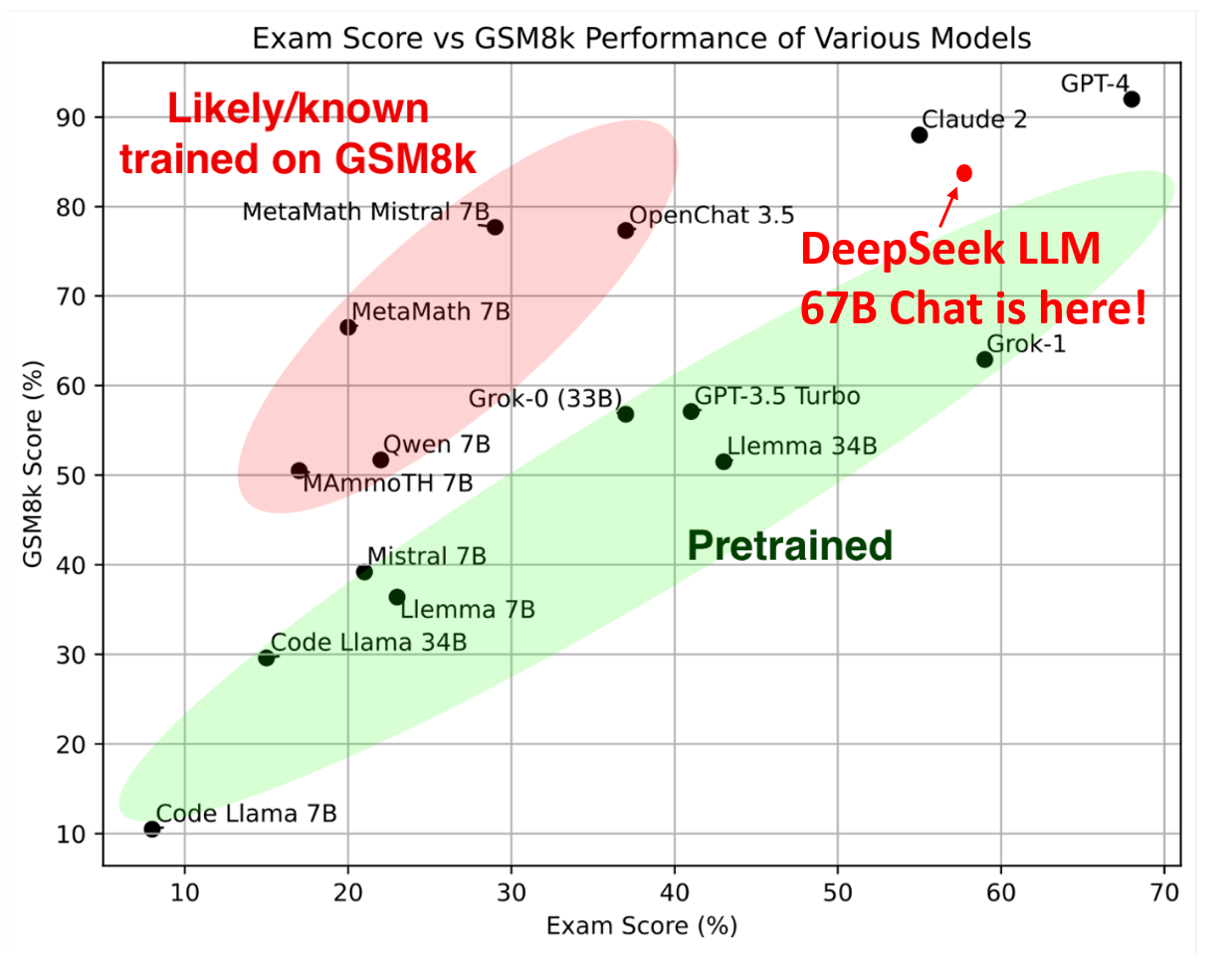
Remark: We have rectified an error from our initial evaluation. In this revised version, we have omitted the lowest scores for questions 16, 17, 18, as well as for the aforementioned image. Evaluation details are here.
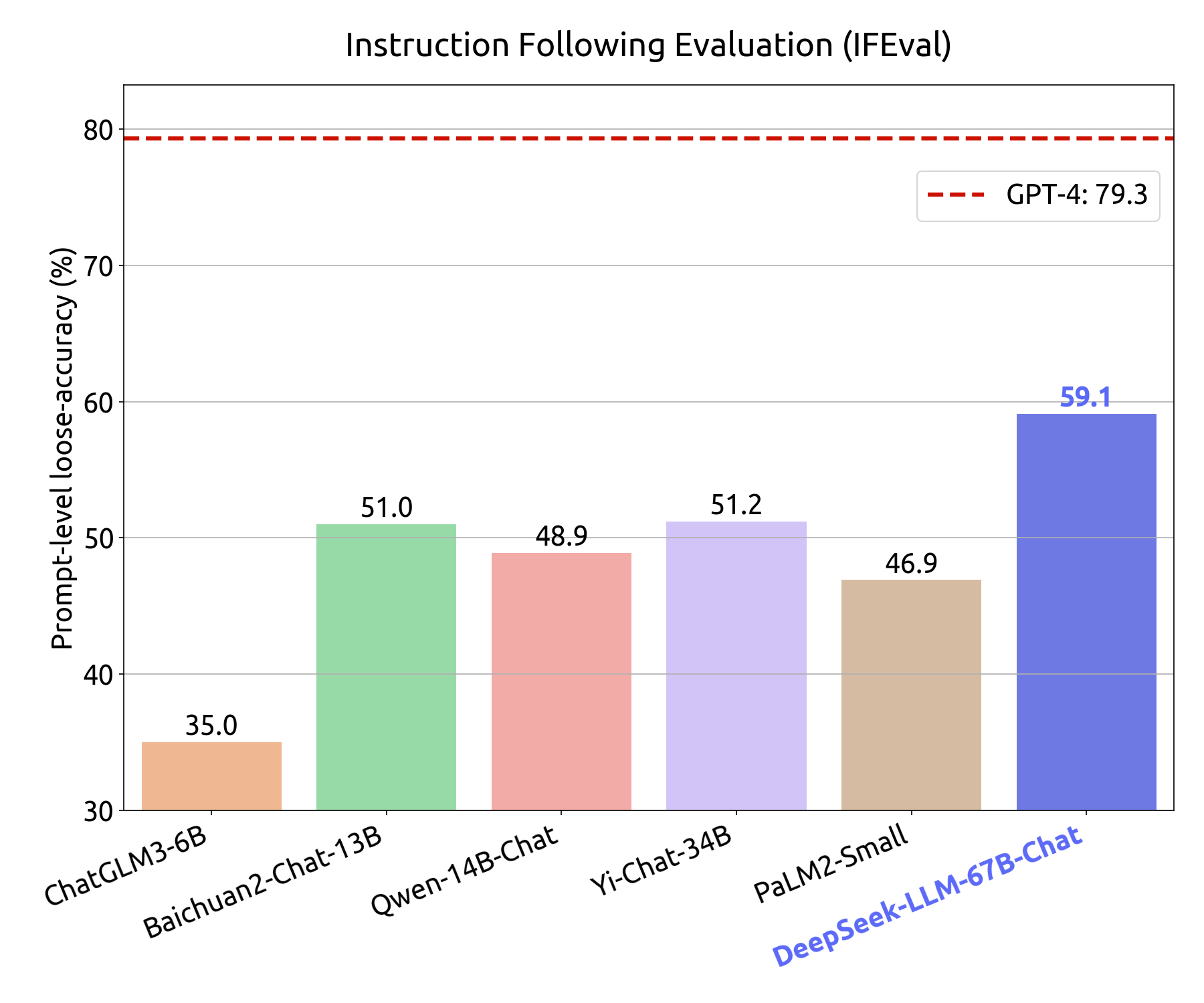
Instruction Following Evaluation: On Nov 15th, 2023, Google released an instruction following evaluation dataset. They identified 25 types of verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We use the prompt-level loose metric to evaluate all models. Here, we used the first version released by Google for the evaluation. For the Google revised test set evaluation results, please refer to the number in our paper.
LeetCode Weekly Contest: To assess the coding proficiency of the model, we have utilized problems from the LeetCode Weekly Contest (Weekly Contest 351-372, Bi-Weekly Contest 108-117, from July 2023 to Nov 2023). We have obtained these problems by crawling data from LeetCode, which consists of 126 problems with over 20 test cases for each. The evaluation metric employed is akin to that of HumanEval. In this regard, if a model’s outputs successfully pass all test cases, the model is considered to have effectively solved the problem. The model’s coding capabilities are depicted in the Figure below, where the y-axis represents the pass@1 score on in-domain human evaluation testing, and the x-axis represents the pass@1 score on out-domain LeetCode Weekly Contest problems.
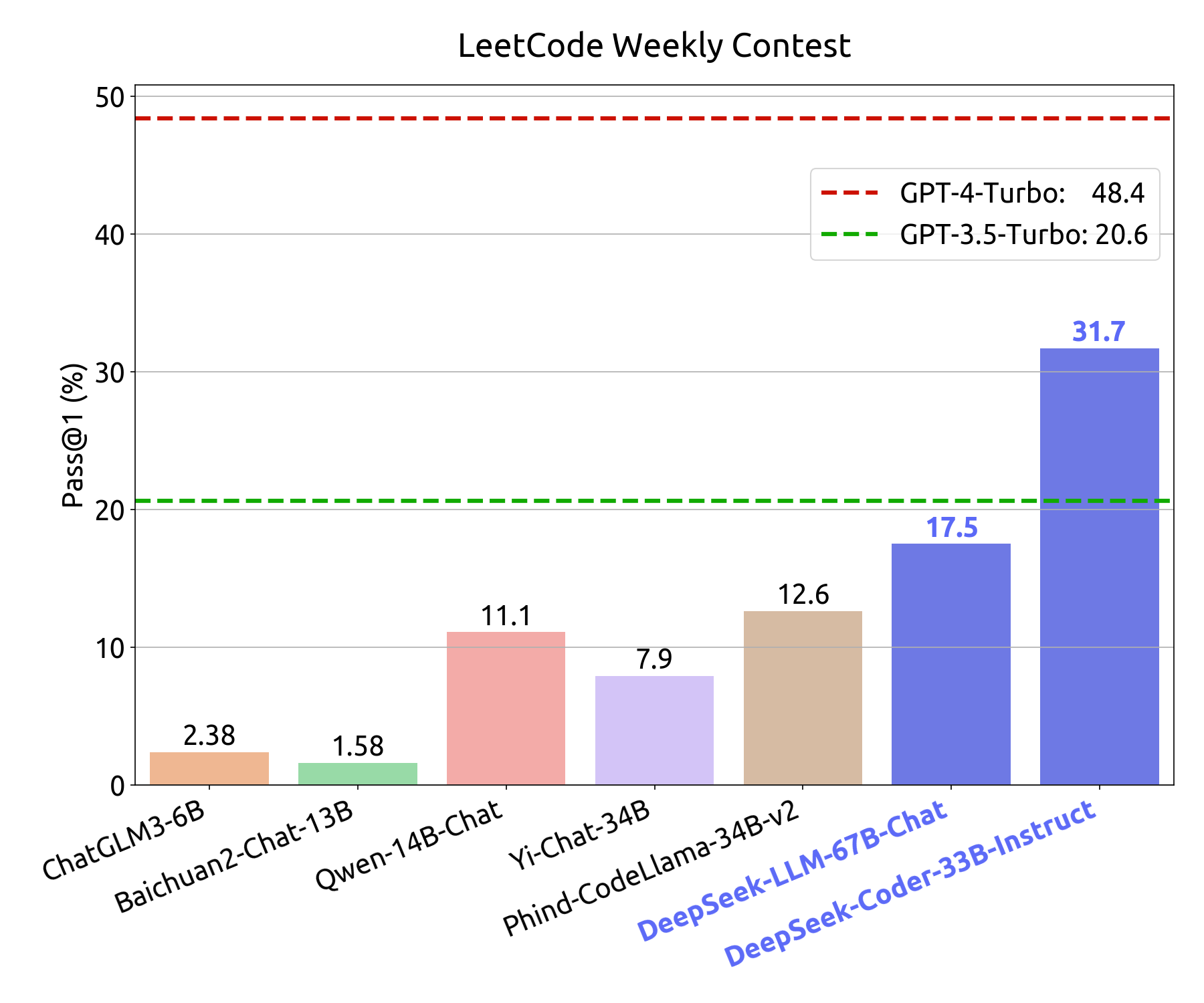
The specific questions and test cases will be released soon. Stay tuned!
Standard Benchmark
| Model | TriviaQA | MMLU | GSM8K | HumanEval | BBH | C-Eval | CMMLU | ChineseQA |
|---|---|---|---|---|---|---|---|---|
| DeepSeek LLM 7B Base | 59.7 | 48.2 | 17.4 | 26.2 | 39.5 | 45.0 | 47.2 | 78.0 |
| DeepSeek LLM 67B Base | 78.9 | 71.3 | 63.4 | 42.7 | 68.7 | 66.1 | 70.8 | 87.6 |
| DeepSeek LLM 7B Chat | 57.9 | 49.4 | 62.6 | 48.2 | 42.3 | 47.0 | 49.7 | 75.0 |
| DeepSeek LLM 67B Chat | 81.5 | 71.1 | 84.1 | 73.8 | 71.7 | 65.2 | 67.8 | 85.1 |
Note: We evaluate chat models with 0-shot for MMLU, GSM8K, C-Eval, and CMMLU. More evaluation results can be found here.
Revisit Multi-Choice Question Benchmarks
Based on our experimental observations, we have discovered that enhancing benchmark performance using multi-choice (MC) questions, such as MMLU, CMMLU, and C-Eval, is a relatively straightforward task. By incorporating multi-choice questions from Chinese exams, we have achieved exceptional results, as depicted in the table below:
| Model | MMLU | C-Eval | CMMLU |
|---|---|---|---|
| DeepSeek LLM 7B Chat | 49.4 | 47.0 | 49.7 |
| DeepSeek LLM 7B Chat + MC | 60.9 | 71.3 | 73.8 |
Note: +MC represents the addition of 20 million Chinese multiple-choice questions collected from the web. It is important to note that we conducted deduplication for the C-Eval validation set and CMMLU test set to prevent data contamination. This addition not only improves Chinese multiple-choice benchmarks but also enhances English benchmarks. However, we observed that it does not enhance the model’s knowledge performance on other evaluations that do not utilize the multiple-choice style in the 7B setting. As a result, we made the decision to not incorporate MC data in the pre-training or fine-tuning process, as it would lead to overfitting on benchmarks.
4. Pre-Training Details
Data
Our primary goal is to holistically enhance the dataset’s richness and variety. To achieve this, we’ve implemented multiple methods and established a distributed, frequent-checkpointing batch processing system, named “cc_cleaner”, to bolster our data pipeline.
Our minimal viable solution departs from RefinedWeb + CCNet. We greatly appreciate their selfless dedication to the research of AGI.
We have also significantly incorporated deterministic randomization into our data pipeline. This approach enables us to continuously enhance our data throughout the lengthy and unpredictable training process.
Data Composition: Our training data comprises a diverse mix of Internet text, math, code, books, and self-collected data respecting robots.txt. In addition to the diverse content, we place a high priority on personal privacy and copyright protection. All content containing personal information or subject to copyright restrictions has been removed from our dataset.
Dataset Pruning: Our system employs heuristic rules and models to refine our training data. Our filtering process removes low-quality web data while preserving precious low-resource knowledge. It aims to improve overall corpus quality and remove harmful or toxic content.
Deduplication: Our advanced deduplication system, using MinhashLSH, strictly removes duplicates both at document and string levels. This rigorous deduplication process ensures exceptional data uniqueness and integrity, especially crucial in large-scale datasets.
Pre-Training
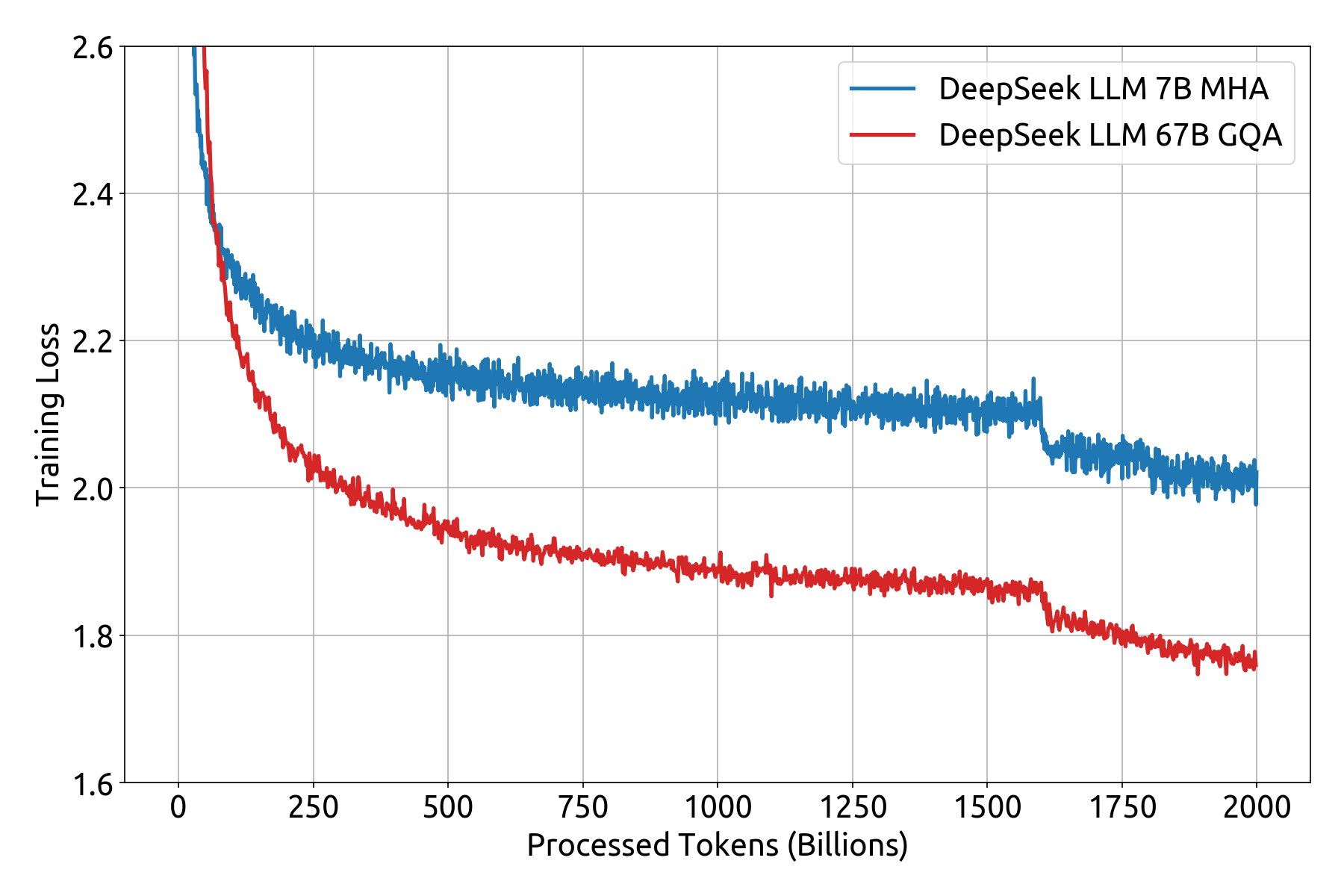
DeepSeek LM models use the same architecture as LLaMA, an auto-regressive transformer decoder model. The 7B model uses Multi-Head attention (MHA) while the 67B model uses Grouped-Query Attention (GQA).
We pre-trained DeepSeek language models on a vast dataset of 2 trillion tokens, with a sequence length of 4096 and AdamW optimizer. The 7B model’s training involved a batch size of 2304 and a learning rate of 4.2e-4 and the 67B model was trained with a batch size of 4608 and a learning rate of 3.2e-4. We employ a multi-step learning rate schedule in our training process. The learning rate begins with 2000 warmup steps, and then it is stepped to 31.6% of the maximum at 1.6 trillion tokens and 10% of the maximum at 1.8 trillion tokens.
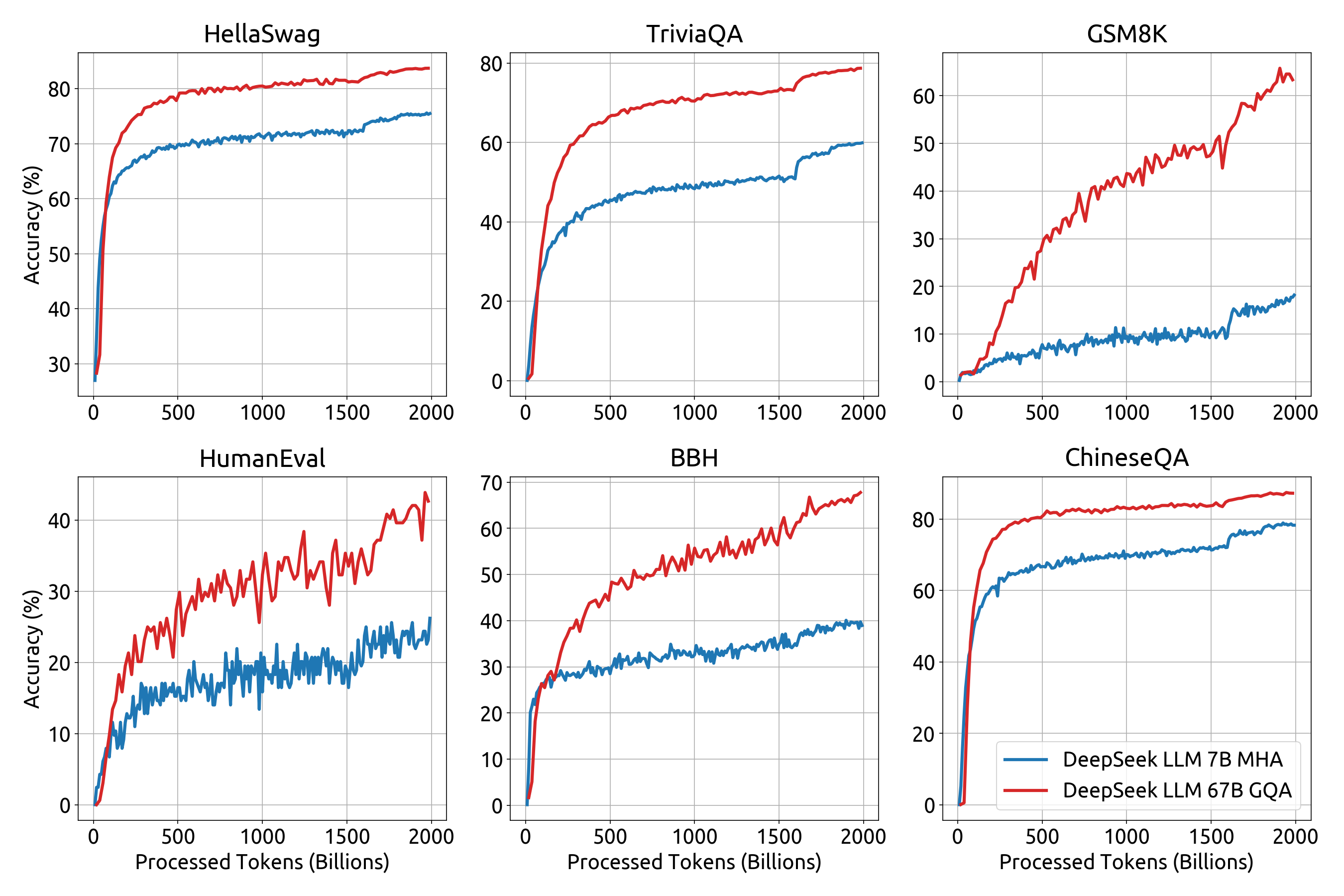
We release the training loss curve and several benchmark metrics curves, as detailed below.
5. Quick Start
Installation
On the basis of Python >= 3.8 environment, install the necessary dependencies by running the following command:
pip install -r requirements.txt
Inference with Huggingface’s Transformers
You can directly employ Huggingface’s Transformers for model inference.
Text Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-llm-67b-base"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
text = "An attention function can be described as mapping a query and a set of key-value pairs to an output, where the query, keys, values, and output are all vectors. The output is"
inputs = tokenizer(text, return_tensors="pt")
outputs = model.generate(**inputs.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Chat Completion
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, GenerationConfig
model_name = "deepseek-ai/deepseek-llm-67b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16, device_map="auto")
model.generation_config = GenerationConfig.from_pretrained(model_name)
model.generation_config.pad_token_id = model.generation_config.eos_token_id
messages = [
{"role": "user", "content": "Who are you?"}
]
input_tensor = tokenizer.apply_chat_template(messages, add_generation_prompt=True, return_tensors="pt")
outputs = model.generate(input_tensor.to(model.device), max_new_tokens=100)
result = tokenizer.decode(outputs[0][input_tensor.shape[1]:], skip_special_tokens=True)
print(result)
Avoiding the use of the provided function apply_chat_template, you can also interact with our model following the sample template. Note that messages should be replaced by your input.
User: {messages[0]['content']}
Assistant: {messages[1]['content']}<|end▁of▁sentence|>User: {messages[2]['content']}
Assistant:
Note: By default (add_special_tokens=True), our tokenizer automatically adds a bos_token (<|begin▁of▁sentence|>) before the input text. Additionally, since the system prompt is not compatible with this version of our models, we DO NOT RECOMMEND including the system prompt in your input.
Inference with vLLM
You can also employ vLLM for high-throughput inference.
Text Completion
from vllm import LLM, SamplingParams
tp_size = 4 # Tensor Parallelism
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100)
model_name = "deepseek-ai/deepseek-llm-67b-base"
llm = LLM(model=model_name, trust_remote_code=True, gpu_memory_utilization=0.9, tensor_parallel_size=tp_size)
prompts = [
"If everyone in a country loves one another,",
"The research should also focus on the technologies",
"To determine if the label is correct, we need to"
]
outputs = llm.generate(prompts, sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
Chat Completion
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
tp_size = 4 # Tensor Parallelism
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=100)
model_name = "deepseek-ai/deepseek-llm-67b-chat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
llm = LLM(model=model_name, trust_remote_code=True, gpu_memory_utilization=0.9, tensor_parallel_size=tp_size)
messages_list = [
[{"role": "user", "content": "Who are you?"}],
[{"role": "user", "content": "What can you do?"}],
[{"role": "user", "content": "Explain Transformer briefly."}],
]
# Avoid adding bos_token repeatedly
prompt_token_ids = [tokenizer.apply_chat_template(messages, add_generation_prompt=True) for messages in messages_list]
sampling_params.stop = [tokenizer.eos_token]
outputs = llm.generate(prompt_token_ids=prompt_token_ids, sampling_params=sampling_params)
generated_text = [output.outputs[0].text for output in outputs]
print(generated_text)
6. FAQ
Could You Provide the tokenizer.model File for Model Quantization?
DeepSeek LLM utilizes the HuggingFace Tokenizer to implement the Byte-level BPE algorithm, with specially designed pre-tokenizers to ensure optimal performance. Currently, there is no direct way to convert the tokenizer into a SentencePiece tokenizer. We are contributing to the open-source quantization methods facilitate the usage of HuggingFace Tokenizer.
GGUF(llama.cpp)
We have submitted a PR to the popular quantization repository llama.cpp to fully support all HuggingFace pre-tokenizers, including ours.
While waiting for the PR to be merged, you can generate your GGUF model using the following steps:
git clone https://github.com/DOGEwbx/llama.cpp.git
cd llama.cpp
git checkout regex_gpt2_preprocess
# set up the environment according to README
make
python3 -m pip install -r requirements.txt
# generate GGUF model
python convert-hf-to-gguf.py <MODEL_PATH> --outfile <GGUF_PATH> --model-name deepseekllm
# use q4_0 quantization as an example
./quantize <GGUF_PATH> <OUTPUT_PATH> q4_0
./main -m <OUTPUT_PATH> -n 128 -p <PROMPT>
GPTQ(exllamav2)
UPDATE:exllamav2 has been able to support HuggingFace Tokenizer. Please pull the latest version and try out.
GPU Memory Usage
We profile the peak memory usage of inference for 7B and 67B models at different batch size and sequence length settings.
For DeepSeek LLM 7B, we utilize 1 NVIDIA A100-PCIE-40GB GPU for inference.
| Batch Size | Sequence Length | ||||
|---|---|---|---|---|---|
| 256 | 512 | 1024 | 2048 | 4096 | |
| 1 | 13.29 GB | 13.63 GB | 14.47 GB | 16.37 GB | 21.25 GB |
| 2 | 13.63 GB | 14.39 GB | 15.98 GB | 19.82 GB | 29.59 GB |
| 4 | 14.47 GB | 15.82 GB | 19.04 GB | 26.65 GB | OOM |
| 8 | 15.99 GB | 18.71 GB | 25.14 GB | 35.19 GB | OOM |
| 16 | 19.06 GB | 24.52 GB | 37.28 GB | OOM | OOM |
For DeepSeek LLM 67B, we utilize 8 NVIDIA A100-PCIE-40GB GPUs for inference.
| Batch Size | Sequence Length | ||||
|---|---|---|---|---|---|
| 256 | 512 | 1024 | 2048 | 4096 | |
| 1 | 16.92 GB | 17.11 GB | 17.66 GB | 20.01 GB | 33.23 GB |
| 2 | 17.04 GB | 17.28 GB | 18.55 GB | 25.27 GB | OOM |
| 4 | 17.20 GB | 17.80 GB | 21.28 GB | 33.71 GB | OOM |
| 8 | 17.59 GB | 19.25 GB | 25.69 GB | OOM | OOM |
| 16 | 18.17 GB | 21.69 GB | 34.54 GB | OOM | OOM |
7. Limitation
While DeepSeek LLMs have demonstrated impressive capabilities, they are not without their limitations. Here are some potential drawbacks of such models:
Over-reliance on training data: These models are trained on vast amounts of text data, which can introduce biases present in the data. They may inadvertently generate biased or discriminatory responses, reflecting the biases prevalent in the training data.
Hallucination: The model sometimes generates responses or outputs that may sound plausible but are factually incorrect or unsupported. This can occur when the model relies heavily on the statistical patterns it has learned from the training data, even if those patterns do not align with real-world knowledge or facts.
Repetition: The model may exhibit repetition in their generated responses. This repetition can manifest in various ways, such as repeating certain phrases or sentences, generating redundant information, or producing repetitive structures in the generated text. This issue can make the output of LLMs less diverse and less engaging for users.
8. License
This code repository is licensed under the MIT License. The use of DeepSeek LLM Base/Chat models is subject to the Model License. DeepSeek LLM series (including Base and Chat) supports commercial use.
9. Citation
@article{deepseek-llm,
author = {DeepSeek-AI},
title = {DeepSeek LLM: Scaling Open-Source Language Models with Longtermism},
journal = {arXiv preprint arXiv:2401.02954},
year = {2024},
url = {https://github.com/deepseek-ai/DeepSeek-LLM}
}
10. Contact
If you have any questions, please raise an issue or contact us at service@deepseek.com.