
Reasoning with Foundation Models
❖ We organize the current foundation models into three categories: language foundation models, vision foundation models, and multimodal foundation models. Further, we elaborate the foundation models in reasoning tasks, including commonsense, mathematical, logical, causal, visual, audio, multimodal, agent reasoning, etc. Reasoning techniques, including pre-training, fine-tuning, alignment training, mixture of experts, in-context learning, and autonomous agent, are also summarized.

DeepSeek LLM
❖ Introducing DeepSeek LLM, an advanced language model comprising 67 billion parameters. It has been trained from scratch on a vast dataset of 2 trillion tokens in both English and Chinese. In order to foster research, we have made DeepSeek LLM 7B/67B Base and DeepSeek LLM 7B/67B Chat open source for the research community.

Accelerating Generative AI with PyTorch
❖ Over the past year, generative AI use cases have exploded in popularity. Text generation has been one particularly popular area, with lots of innovation among open-source projects such as llama.cpp, vLLM, and MLC-LLM. While these projects are performant, they often come with tradeoffs in ease of use, such as requiring model conversion to specific formats or building and shipping new dependencies. This begs the question: how fast can we run transformer inference with only pure, native PyTorch?
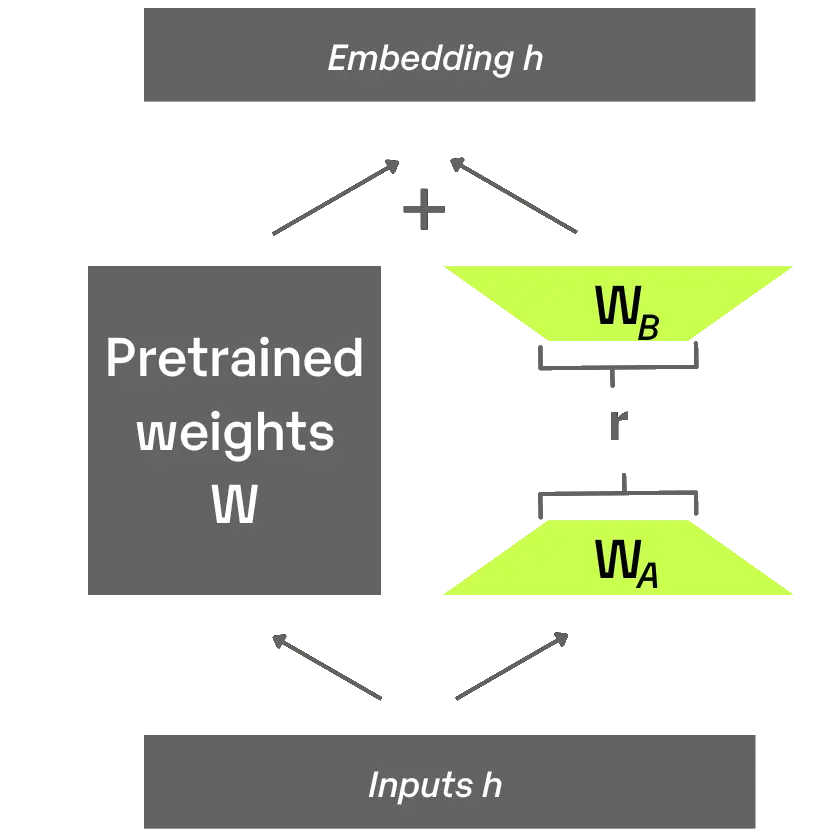
S-LoRA
❖ We introduce S-LoRA (code), a system designed for the scalable serving of many LoRA adapters. S-LoRA adopts the idea of Unified Paging for KV cache and adapter weights to reduce memory fragmentation. Heterogeneous Batching of LoRA computation with different ranks leveraging optimized custom CUDA kernels which are aligned with the memory pool design. S-LoRA TP to ensure effective parallelization across multiple GPUs, incurring minimal communication cost for the added LoRA computation compared to that of the base model.

DeepSpeed-FastGen
❖ Large language models (LLMs) like GPT-4 and LLaMA have emerged as a dominant workload in serving a wide range of applications infused with AI at every level. While frameworks like DeepSpeed, PyTorch, and several others can regularly achieve good hardware utilization during LLM training, the interactive nature of these applications and the poor arithmetic intensity of tasks like open-ended text generation have become the bottleneck for inference throughput in existing systems.

vLLM
❖ LLMs promise to fundamentally change how we use AI across all industries. However, actually serving these models is challenging and can be surprisingly slow even on expensive hardware. We are excited to introduce vLLM, an open-source library for fast LLM inference and serving. vLLM utilizes PagedAttention, our new attention algorithm that effectively manages attention keys and values. vLLM redefines the new state of the art in LLM serving: it delivers up to 24x higher throughput than HuggingFace Transformers, without requiring any model architecture changes.