This is the introduction of Attention Residuals (AttnRes), a drop-in replacement for standard residual connections in Transformers that enables each layer to selectively aggregate earlier representations via learned, input-dependent attention over depth.
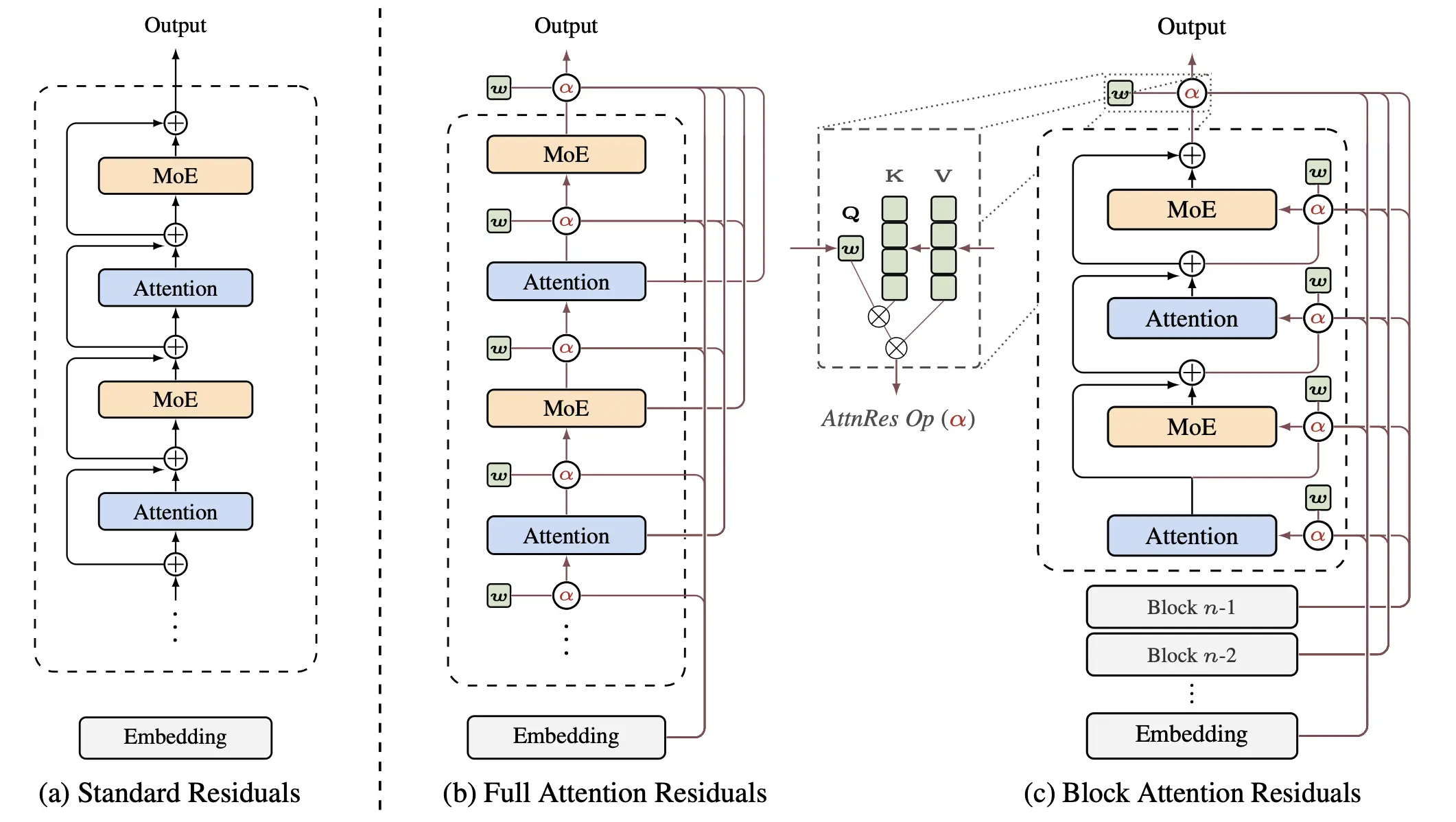
(a) Standard residuals with uniform additive accumulation. (b) Full AttnRes: each layer attends over all previous outputs. (c) Block AttnRes: layers are grouped into blocks, reducing memory from O(Ld) to O(Nd).
Overview
Standard residual connections accumulate all layer outputs with fixed unit weights. As depth grows, this uniform aggregation dilutes each layer’s contribution and causes hidden-state magnitudes to grow unboundedly — a well-known problem with PreNorm.
AttnRes replaces this fixed accumulation with softmax attention over preceding layer outputs:
$$\mathbf{h}_l = \sum_{i=0}^{l-1} \alpha_{i \to l} \cdot \mathbf{v}_i$$
where the weights $\alpha_{i \to l}$ are computed via a single learned pseudo-query $\mathbf{w}_l \in \mathbb{R}^d$ per layer. This gives every layer selective, content-aware access to all earlier representations.
Block AttnRes
Full AttnRes is straightforward but requires O(Ld) memory at scale. Block AttnRes partitions layers into N blocks, accumulates within each block via standard residuals, and applies attention only over block-level representations. With ~8 blocks, it recovers most of Full AttnRes’s gains while serving as a practical drop-in replacement with marginal overhead.
PyTorch-style pseudocode
def block_attn_res(blocks: list[Tensor], partial_block: Tensor, proj: Linear, norm: RMSNorm) -> Tensor:
"""
Inter-block attention: attend over block reps + partial sum.
blocks:
N tensors of shape [B, T, D]: completed block representations for each previous block
partial_block:
[B, T, D]: intra-block partial sum (b_n^i)
"""
V = torch.stack(blocks + [partial_block]) # [N+1, B, T, D]
K = norm(V)
logits = torch.einsum('d, n b t d -> n b t', proj.weight.squeeze(), K)
h = torch.einsum('n b t, n b t d -> b t d', logits.softmax(0), V)
return h
def forward(self, blocks: list[Tensor], hidden_states: Tensor) -> tuple[list[Tensor], Tensor]:
partial_block = hidden_states
# apply block attnres before attn
# blocks already include token embedding
h = block_attn_res(blocks, partial_block, self.attn_res_proj, self.attn_res_norm)
# if reaches block boundary, start new block
# block_size counts ATTN + MLP; each transformer layer has 2
if self.layer_number % (self.block_size // 2) == 0:
blocks.append(partial_block)
partial_block = None
# self-attention layer
attn_out = self.attn(self.attn_norm(h))
partial_block = partial_block + attn_out if partial_block is not None else attn_out
# apply block attnres before MLP
h = block_attn_res(blocks, partial_block, self.mlp_res_proj, self.mlp_res_norm)
# MLP layer
mlp_out = self.mlp(self.mlp_norm(h))
partial_block = partial_block + mlp_out
return blocks, partial_block
Results
Scaling Laws
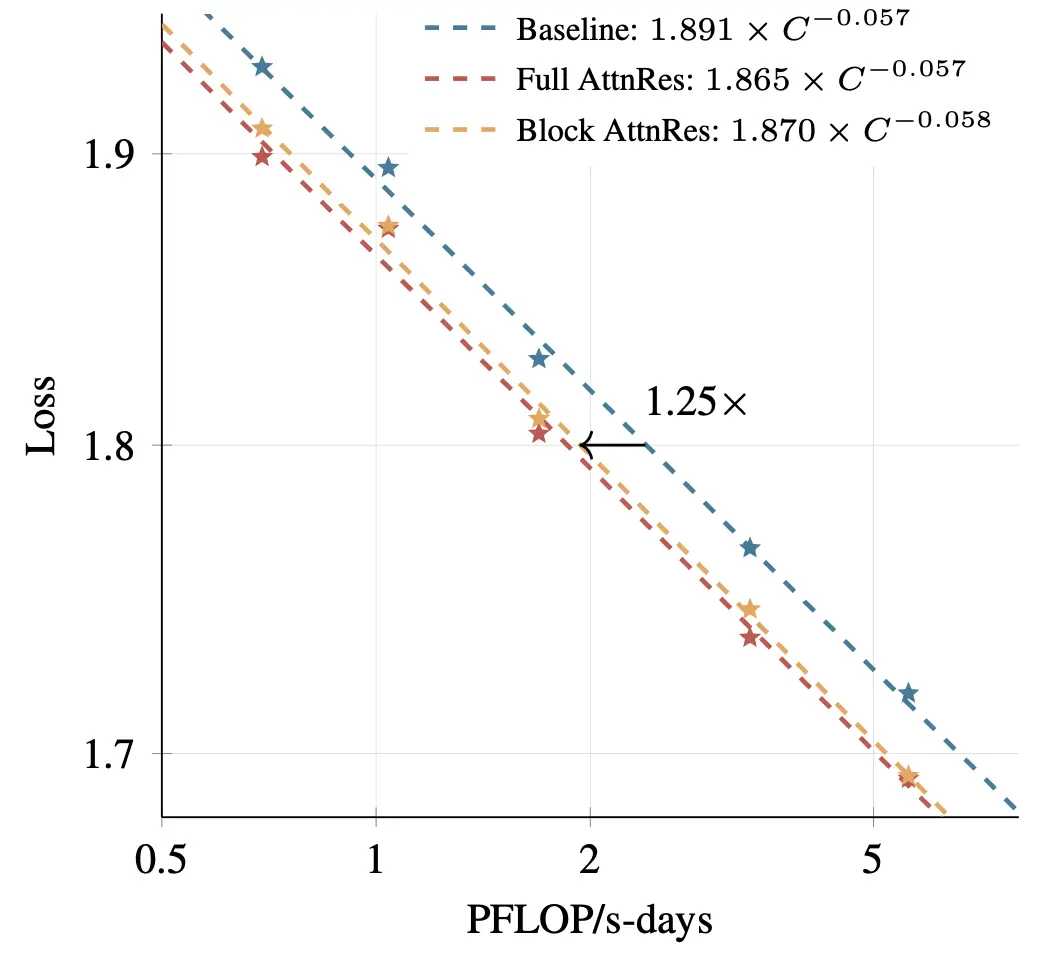
AttnRes consistently outperforms the baseline across all compute budgets. Block AttnRes matches the loss of a baseline trained with 1.25x more compute.
Downstream Performance (Kimi Linear 48B / 3B activated, 1.4T tokens)
| Category | Benchmark | Baseline | AttnRes |
|---|---|---|---|
| General | MMLU | 73.5 | 74.6 |
| GPQA-Diamond | 36.9 | 44.4 | |
| BBH | 76.3 | 78.0 | |
| TriviaQA | 69.9 | 71.8 | |
| Math & Code | Math | 53.5 | 57.1 |
| HumanEval | 59.1 | 62.2 | |
| MBPP | 72.0 | 73.9 | |
| Chinese | CMMLU | 82.0 | 82.9 |
| C-Eval | 79.6 | 82.5 |
AttnRes improves across the board, with the largest gains on multi-step reasoning (+7.5 on GPQA-Diamond) and code generation (+3.1 on HumanEval).
Training Dynamics
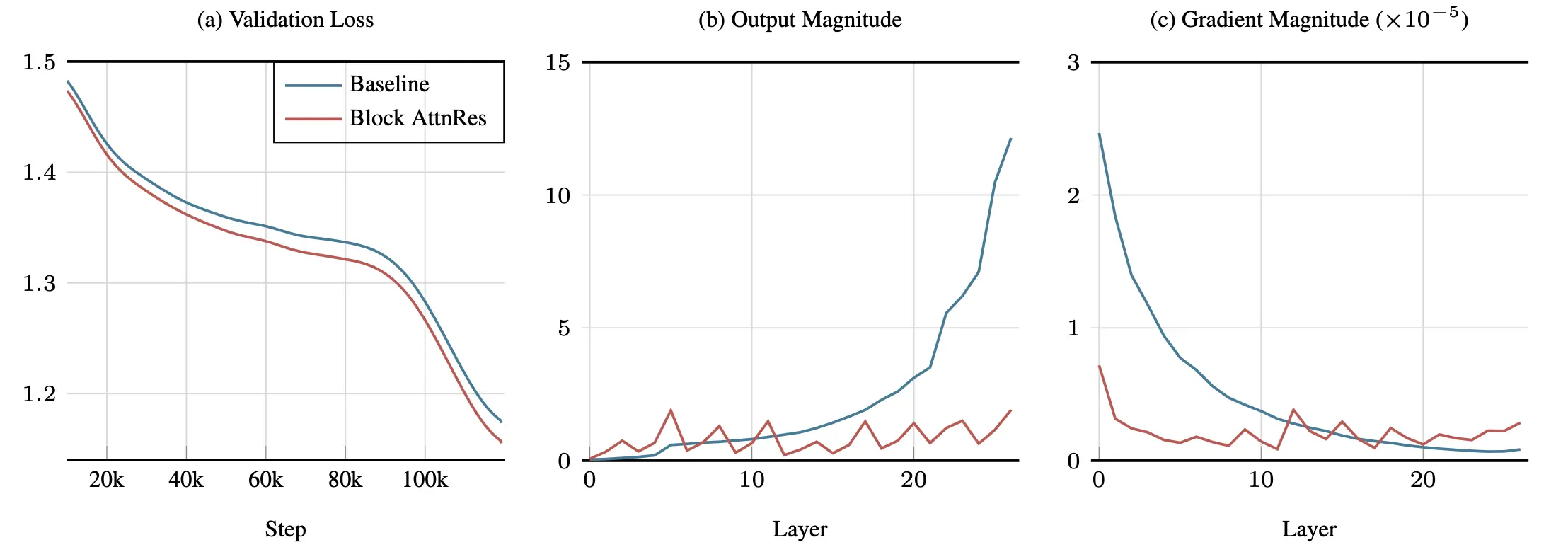
AttnRes mitigates PreNorm dilution: output magnitudes remain bounded across depth and gradient norms distribute more uniformly across layers.
Citation
If you found our work useful, please cite
@misc{chen2026attnres,
title = {Attention Residuals},
author = {Kimi Team and Chen, Guangyu and Zhang, Yu and Su, Jianlin and Xu, Weixin and Pan, Siyuan and Wang, Yaoyu and Wang, Yucheng and Chen, Guanduo and Yin, Bohong and Chen, Yutian and Yan, Junjie and Wei, Ming and Zhang, Y. and Meng, Fanqing and Hong, Chao and Xie, Xiaotong and Liu, Shaowei and Lu, Enzhe and Tai, Yunpeng and Chen, Yanru and Men, Xin and Guo, Haiqing and Charles, Y. and Lu, Haoyu and Sui, Lin and Zhu, Jinguo and Zhou, Zaida and He, Weiran and Huang, Weixiao and Xu, Xinran and Wang, Yuzhi and Lai, Guokun and Du, Yulun and Wu, Yuxin and Yang, Zhilin and Zhou, Xinyu},
year = {2026},
archiveprefix = {arXiv},
eprint = {2603.15031},
primaryclass = {cs.CL}
}